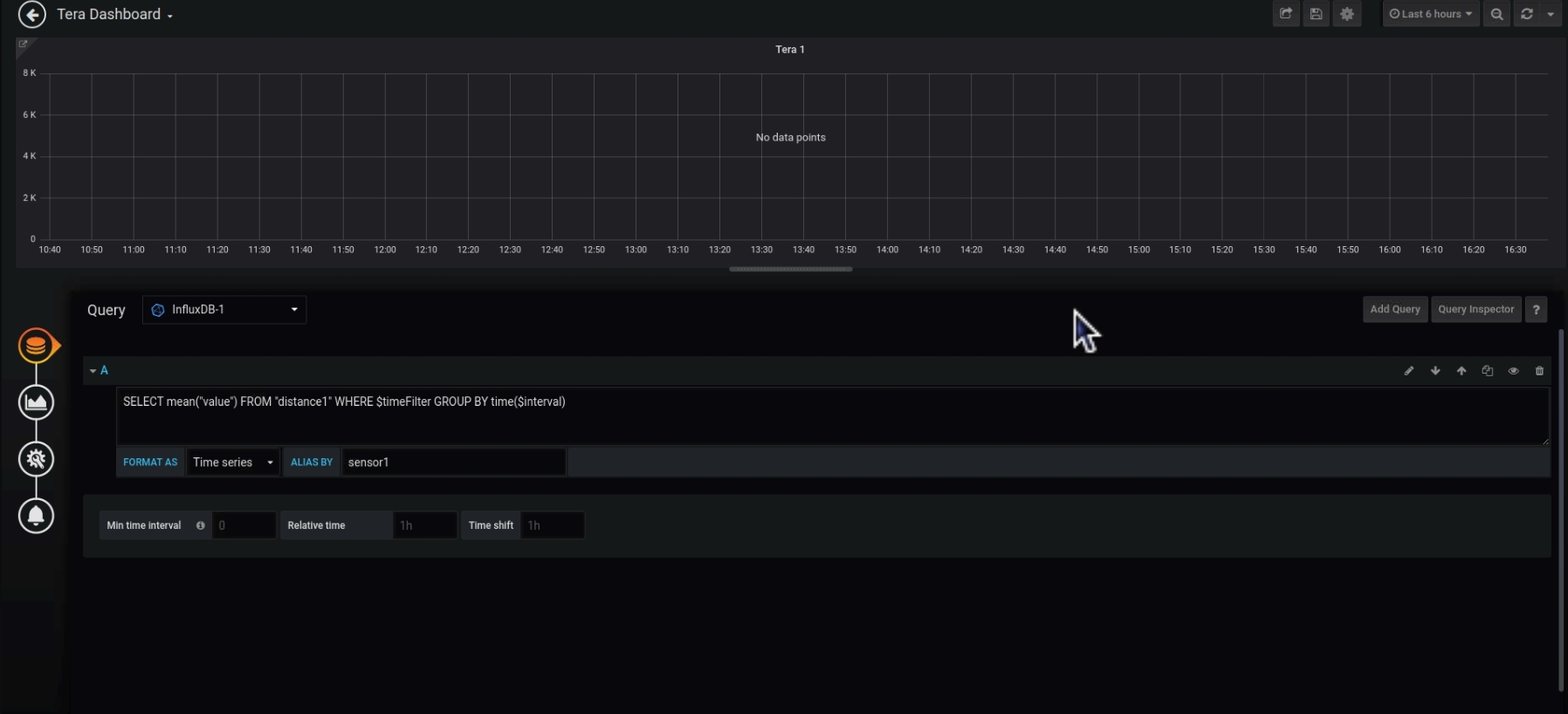
Currently I am accumulating data from a distance sensor in InfluxDB and I got 4 distance values per 1 second. When I put this data into Grafana, I see that the graph is a bit slow to show, possibly given how much data are presented.
In this case on Grafana, is it possible to query like “SELECT value FROM distance” but make it so it will only SELECT every Nth value (ex. 0th, 10th, 20th…) and not all of them?
The is not a best approach, because you ignore collected values. Better approach is to calculated aggregated values, e.g. average for every second:
SELECT MEAN(value)
FROM distance
GROUP BY time(1s)
But 1 datapoint per second can be also too much for long time period (e.g. 1 year), so use Grafana $__interval, which will choose the best time aggregation based on current dashboard time period:
SELECT MEAN(value)
FROM distance
GROUP BY time($__interval)
=> time granularity will be adjusted automatically as you zoom in/out graphs.
I have put your query in as you can see above, but somehow the graph still doesn’t have data. If I only have the basic query of “SELECT “value” FROM “distance1” WHERE $timeFilter”, the graph will have data immediately.
You can check how query looks like (maybe macro is not initialized correctly), what is returned (maybe there is really empty result, or returned timestamps are not correct). You need to troubleshoot on your own. Also be familiar with time grouping - read InfluxDB doc - there are some additional option, e.g. fill()…
Thank you for your guidance. This is my first day on Grafana actually. What went wrong was Node-RED has been sending in distance value of the sensor in string to InfluxDB. That’s why the mean function didn’t work. (Got “ERR: unsupported mean iterator type: *query.stringInterruptIterator” error)
But after I made Node-RED send in the values as Integer with the function node with the code, your suggestion works:
msg.payload = Number(msg.payload);
return msg;
Thank you for pointing out the Query Inspector, Mr. jangaraj.