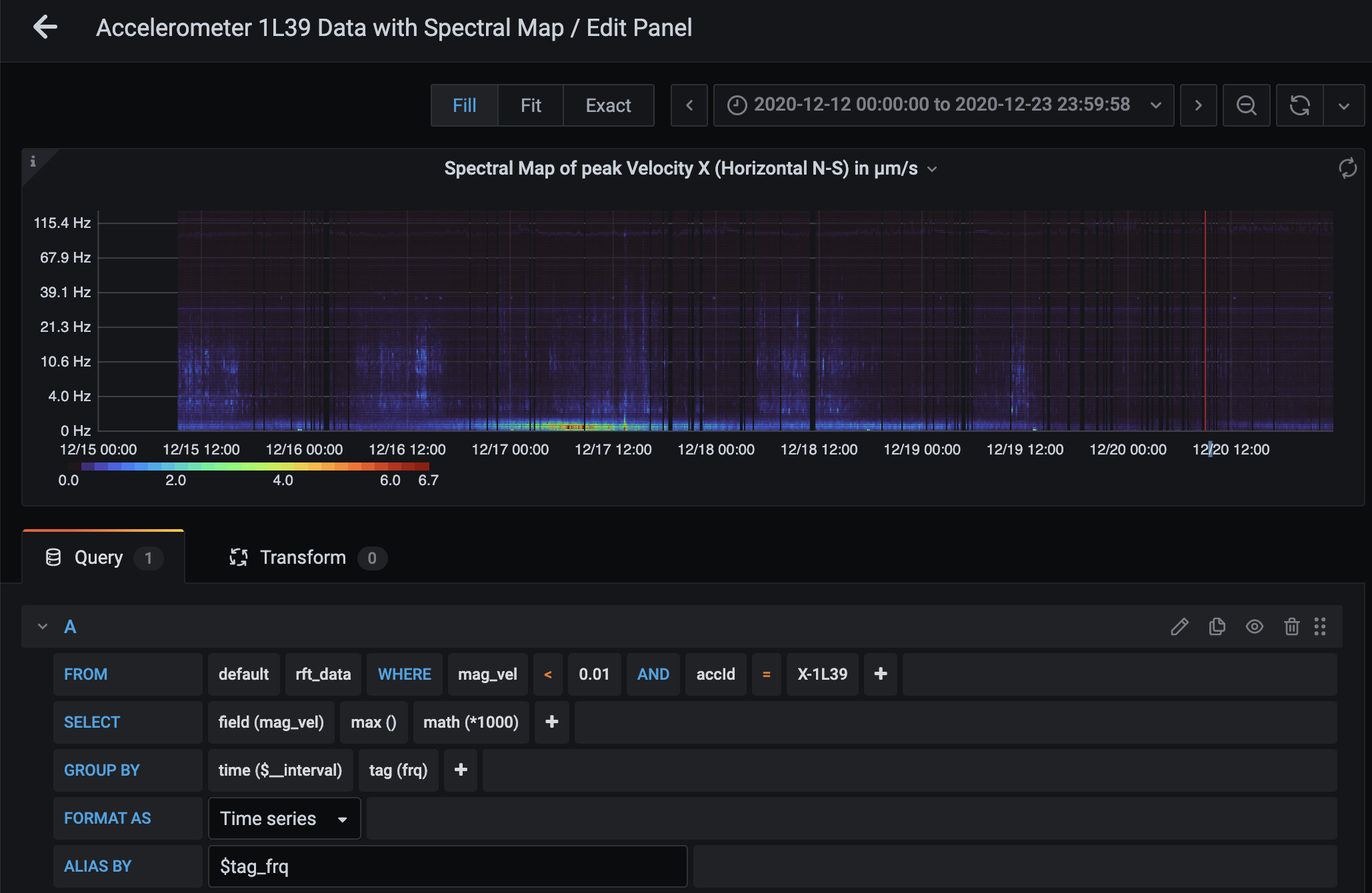
I am generating a heat map for spectral density data via this query:
SELECT “mag_vel” *1000 FROM “rft_data” WHERE (“mag_vel” < 0.01 AND “accId” = ‘X-1L39’) AND time >= now() - 30m GROUP BY “frq”
It’s 128 bins for a logarithmic (pre computed time series buckets) set of frequencies. It is all working great, but for larger time ranges it is getting very very slow. I am not sure how the data it preprocessed, but it seam all data is considered and some how put together. (good, but also very slow) as I have a spectra every 6s if logging is triggered. Up to 6 hours all works fine, but fetching a day or even more is nearly impossible even with patience. Is there any way I could pre process and mark (to only select) a sub set of “peak” data of do something a like?
Any hints?
See screenshot example, this is one of 6 panels total:
Use also time aggregation, so InfluxDB doesn’t need to return so many datapoints. Of course apply some suitable aggregation function for the field, e. g. MEAN.
Let’s say you have one record per second, so InfluxDB can return up to 86400 time unique records per day. There is no way to display of 86400 time records in the Grafana graph width, which has max 4k pixels (if you are happy user of 4k monitor user, it can be even less, e. g. 1k for many standard users).
Also you may kill your browser with so many datapoints. Use Grafana magic macro features and you will get automatic time aggregation based on your current dashboard time range:
Good ideas, but some thing is not working as I expect:
using “group by time($__interval)” returns no data points any more (added this to my GROUP by tag(frq)
using MEAN is giving me a constant in time value, very strange?!?!
using MAX Aggregation would be OK, but I always want a complete “frq” set (column), gaps in time are per design OK and mean: no data, under detection threshold.
The MEAN and/or MAX for a useful data aggregation here would need to operate on “slices” per tag(frq) as a whole, can not consider all data as means or max must be taken in time domain/dimension only. My “series” are tagged with the frequency values as I use for GROUP tag(frg) here. How can I do this?
I didn’t gave you copy paste solution. Time grouping is additional groupping. In the UI query editor mode just click on plus in the group by row and select time groupping.
And don’t expect perfect solution from someone who doesn’t have idea about your data. You have to play and develop that query on your end to fit your needs. It looks like you have really high time frequency so with default Grafana time grouping you will loose metric granularity. That’s fine, you can still customize time grouping, e. g. per 10ms, etc.
I had to use max aggregation together with the time grouping. I tried both separately first to test, that failed! Still do not understand exactly why, but work now just fine!!
My spectra are when recorded stored every 10sec as that’s how long my time window is. No moving window data, that’ll be overly crazy to store… In addition I have a time wave form for the date at much higher rate little over 100/s.



{kind=link}