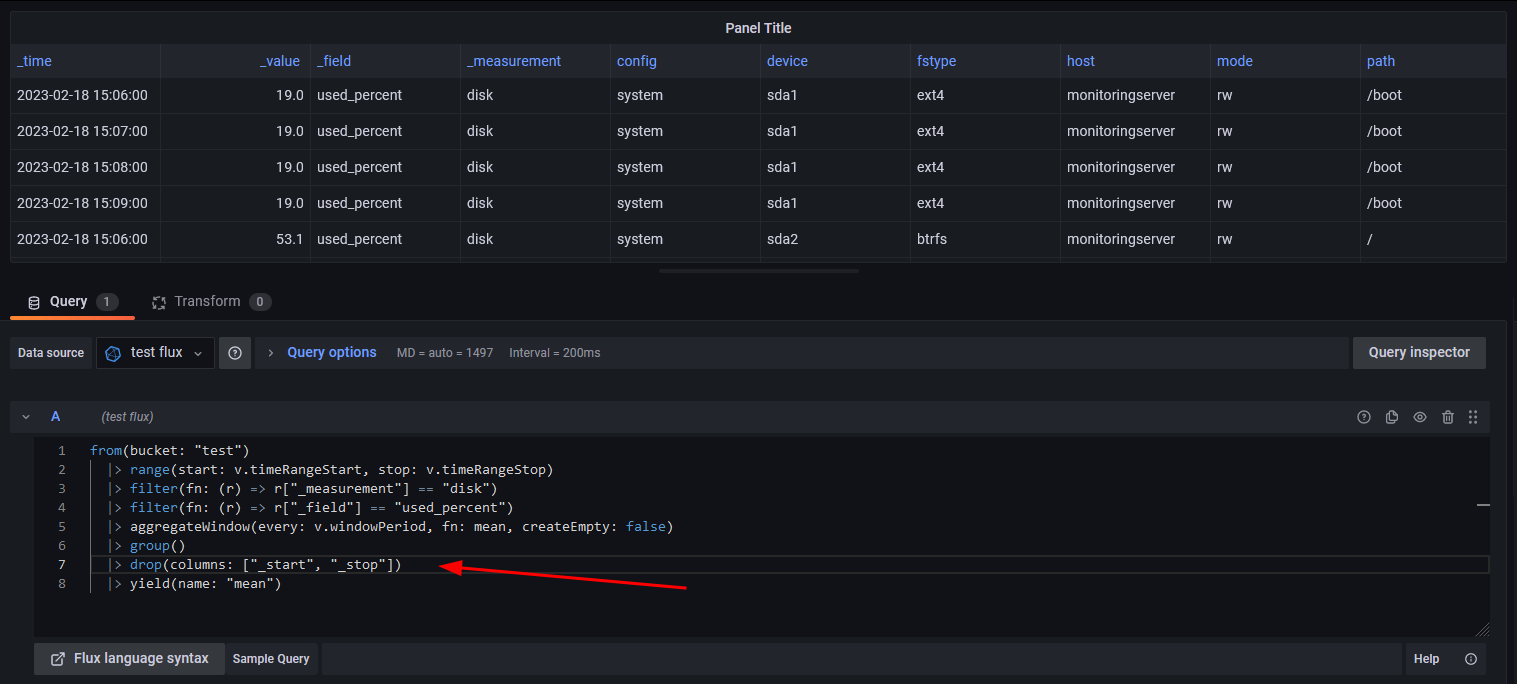
I am using InfluxDB 2.1.1, and Grafana v8.3.2 (afb9e8e5f). The connection is set up with Flux. I want to display basic system logs from a bucket.
I have a few variables set on the dashboard and the query for the a table view is set up like this:
I am guessing the query contains less tables in the response hence the view thinks this is a different structure and the field settings no longer apply. But in my case it is always the same. I even added a Merge hoping that it will “flatten” the tables, but it does not help.
Is it possible to “fix” the transform not allow it to be changed? Or any other way to archive the same result?
I realized, I should have used the Overrides and not the Organize Fields transformation. But correct me if I am wrong.
But it looks like the Overrides still ignores me the order I maintain the fields. And if I only use Organize Fields to set the column order, that still resets after each time range change.
Thank you. I tried that but the column name to be changed (e.g.) Device {_start="2023-02-18 06: etc etc etc } is diferent every time the data is pulled (diferent time stamps). So I am not sure how I can identify the column to be changed to “Device”.
so maybe if my column name is Device {_start="2023-02-18 06: etc etc etc } , I just need a regex expression to find “Device {_start” (i.e. new regex expression - below) and change “${column} (Reserved)” to “${column} (Device)” ?
Hi @ianhud,
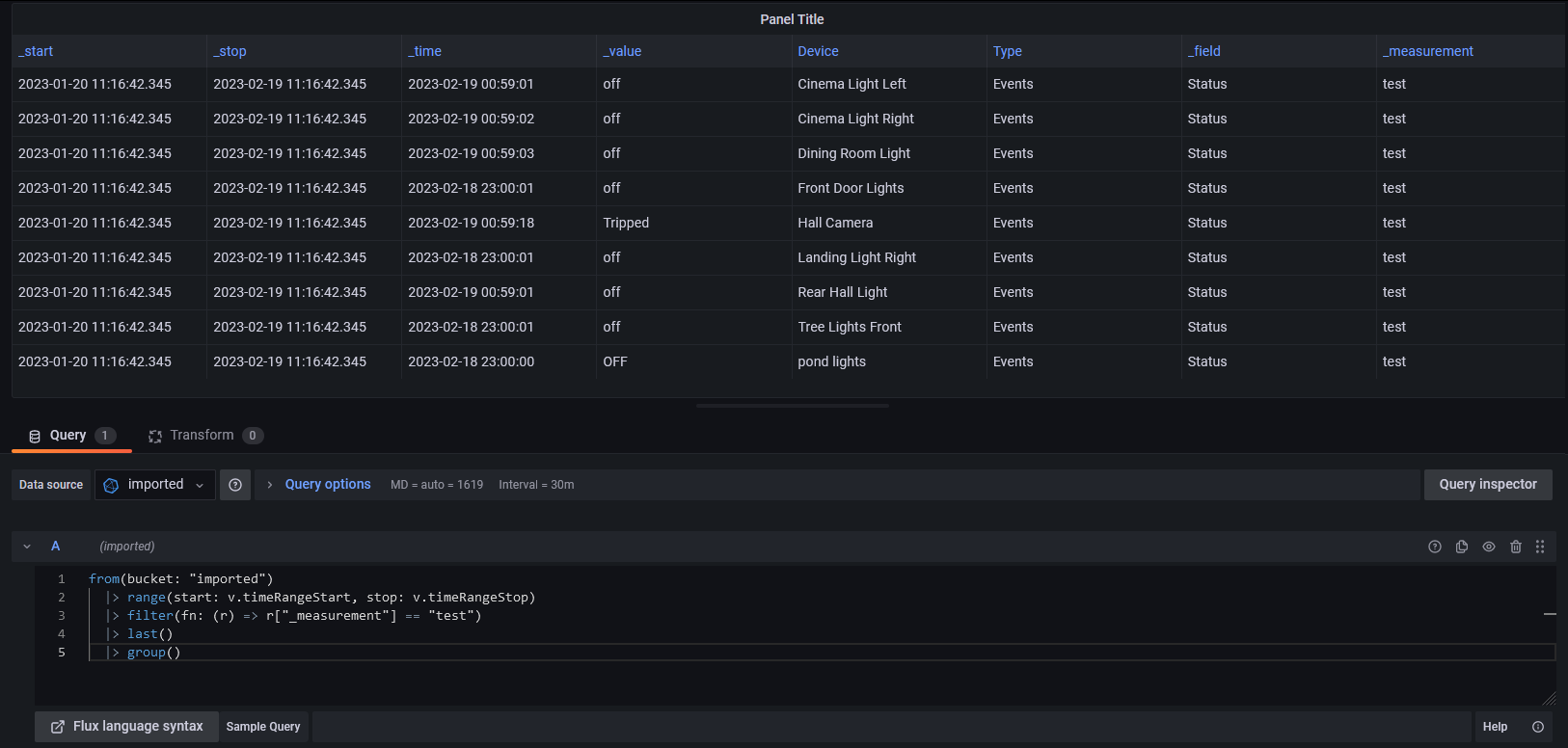
Maybe you can just ungroup data and drop _start and _stop columns?
Default:
Here you can see one column with all tags inside { } brackets and selection box for choosing different tables (in my case they differ in path which is filesystem name).
After ungrouping data ( |> group() function ) you get everything in one table (no selection box) and every tag inside { } brackets becomes a table column:
Q: Is it safe to use last() selector? Would't it print only last value?
A: In this case you will get all rows because data is grouped by _measurement, _field, _start, _stop, Device, Type. You can see that in InfluxDB if you toggle “View Raw Data” and check table header (marked with rectangle).
Be aware that when you use “View Raw Data” option in InfluxDB you will always see all results in one table but you might have stream of tables in reality (like in this case).
Now, if you set Table view in InfluxDB and turn off “View Raw Data” you will see that you in fact have a stream of tables (if you are not using group() function).
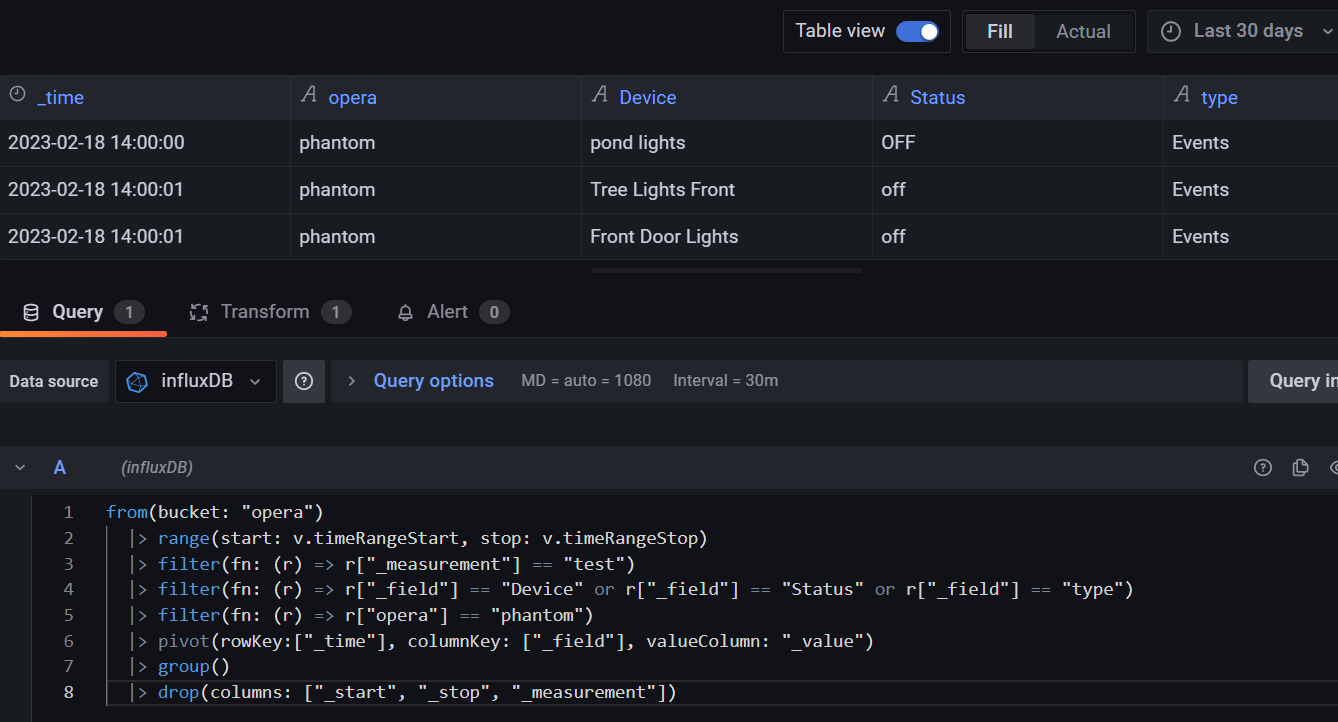
That is very kind of you to spend time investigating. I don’t think it is safe for me to use last(). It is true the data in the csv’s only had one entry per table but that is becuase they were entries from last 3 hours. If I query a longer timeframe e.g. last 24 hours then tables have multiple entries.