Hi there,
I used the display name function of grafana to define my own name:
${__field.name} ${__series.name} [${__field.labels.Eenheid}]

The result is shown below:
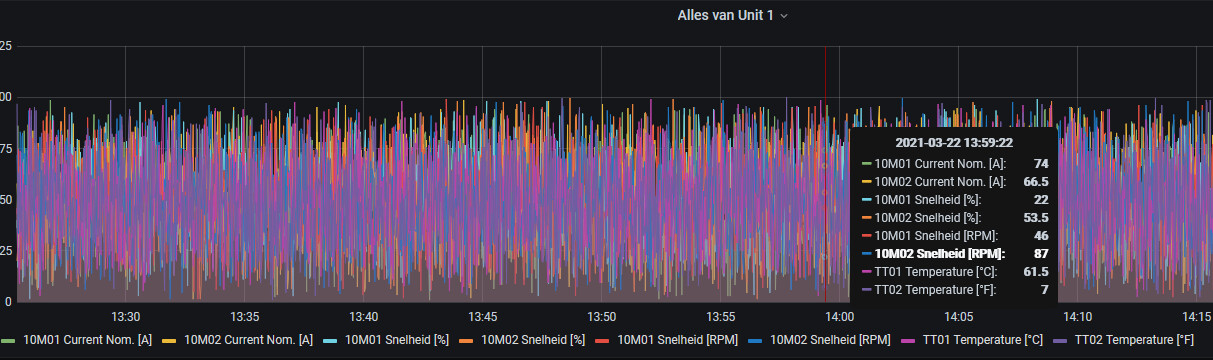
Hi there,
I used the display name function of grafana to define my own name:
${__field.name} ${__series.name} [${__field.labels.Eenheid}]
The result is shown below: