- What Grafana version and what operating system are you using?
Grafana 10.0.10, Windows 10 Enterprise
Caveat: I’m new, and probably lack the terminologies to phrase my questions properly.
- What are you trying to achieve?
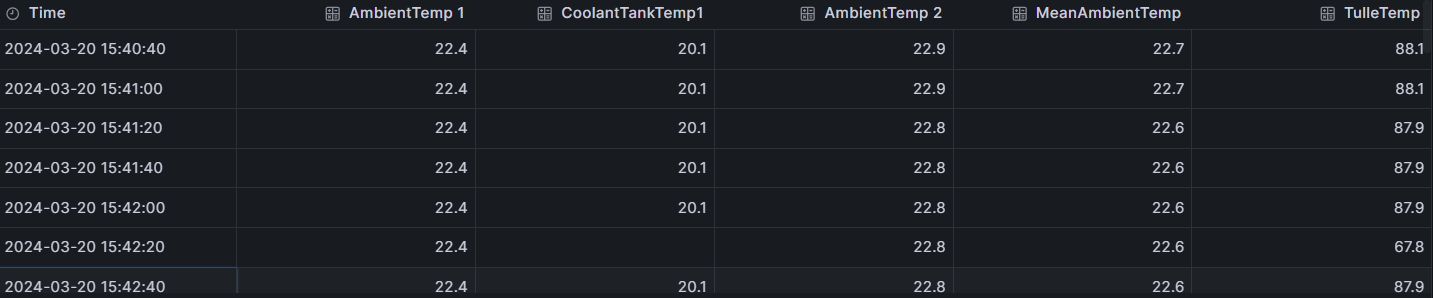
I want my panel to skip rows where there are missing sensor data, and not show them with gaps and dips as seen below when ‘CoolantTankTemp1’ fails to update at time 10:54:40 and 10:57:00. I know how to “gloss” over gaps by connecting null points in the options. However the gaps still persist in the dataset, resulting in two sharp dips when using the sensor data to calculate a new dummy-value. These dips don’t disappear by connecting nullpoints. The dips aren’t really there, and shouldn’t be visualized.

- How are you trying to achieve it?
I though/hoped I could use ‘Join by field’ (Inner) transform to simply remove the affected rows. I realize this would be a rather brute force method, but in this case it isn’t a big deal to lose a few.
This worked when I read temperatures from two different machines and averaged the temperature between them, but not now, when I read from just one.
- Can you copy/paste the configuration(s) that you are having problems with?
SELECT
time_bucket('20 sec', time) AS time, --
part AS metric, --metric adds id-number to equal parts (sensors)
MAX(value) --sensor readings
FROM temp --temperature dataset
WHERE
temp.machineno = '$MachineNo'
AND $__timeFilter(time)
AND value < 30 AND value > 0
GROUP BY time, part
ORDER BY time