Hi,
I’m using Grafana 9.3.2 on Oracle Linux Server 8.7.
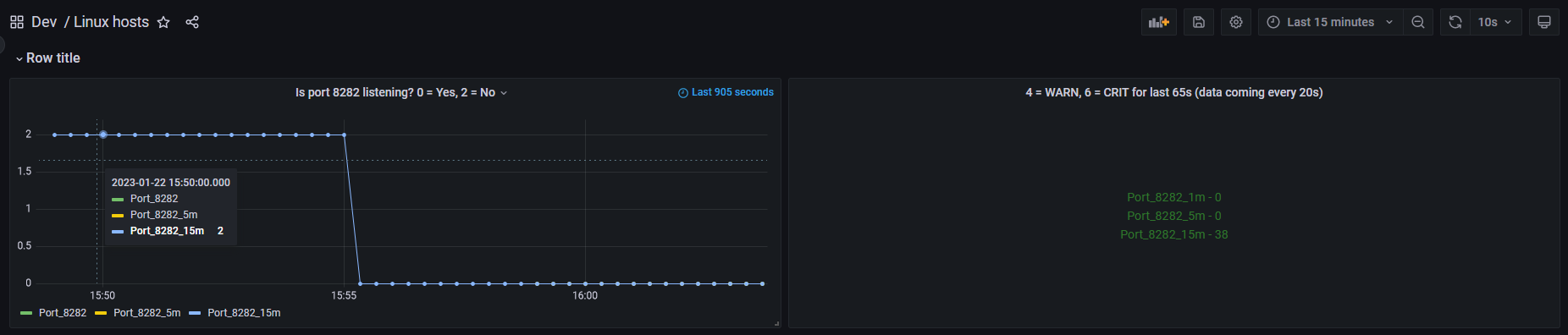
I am attempting to display a server up status over time. Depending on how many times up has returned 0 in the past 15 minutes, display either statuses from green, to yellow, to red. Also, show the up count. At present I am attempting to just get this to work for a couple of servers. Once I can prove the concept, I hope to use a template to show a panel of servers.
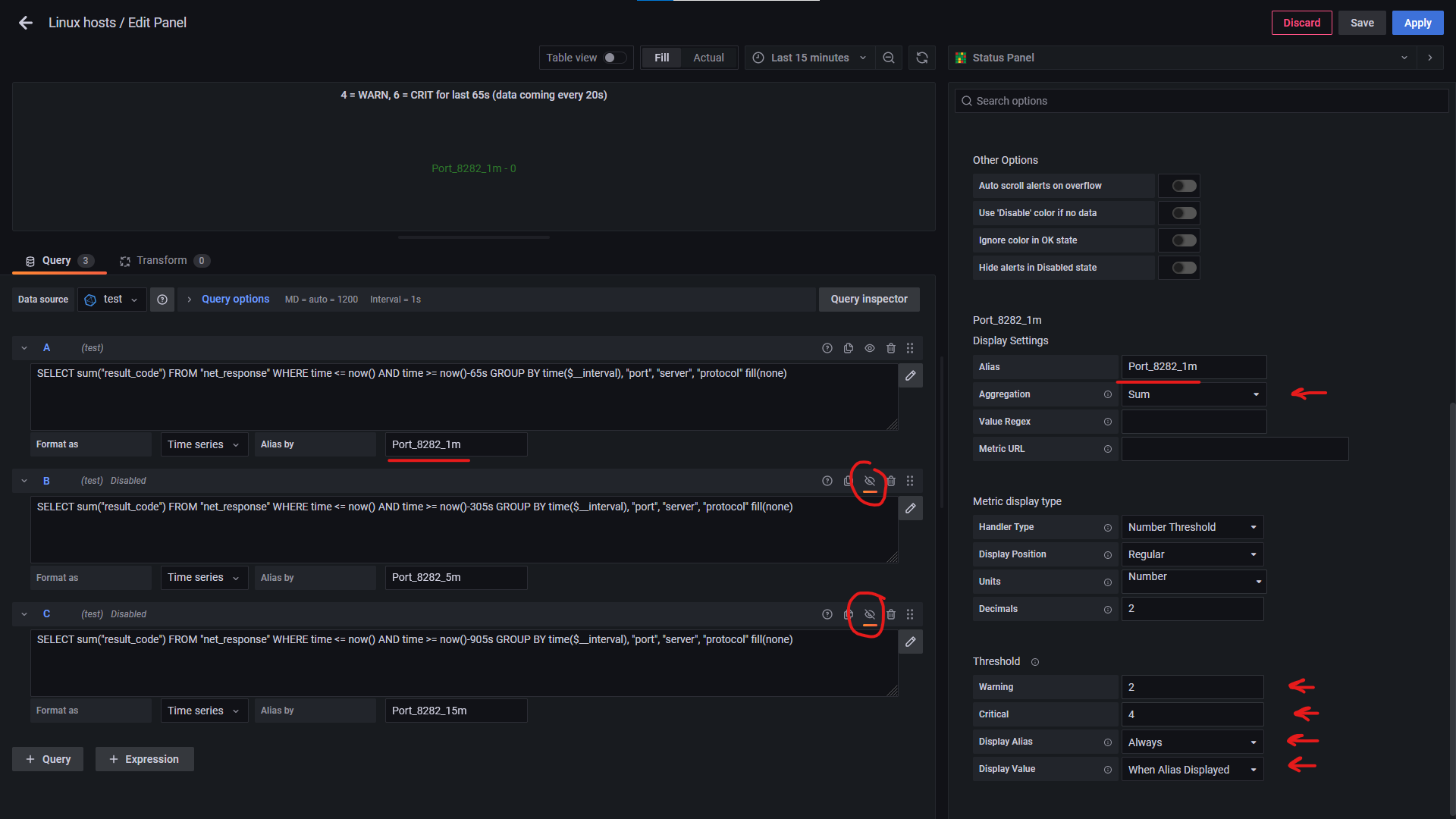
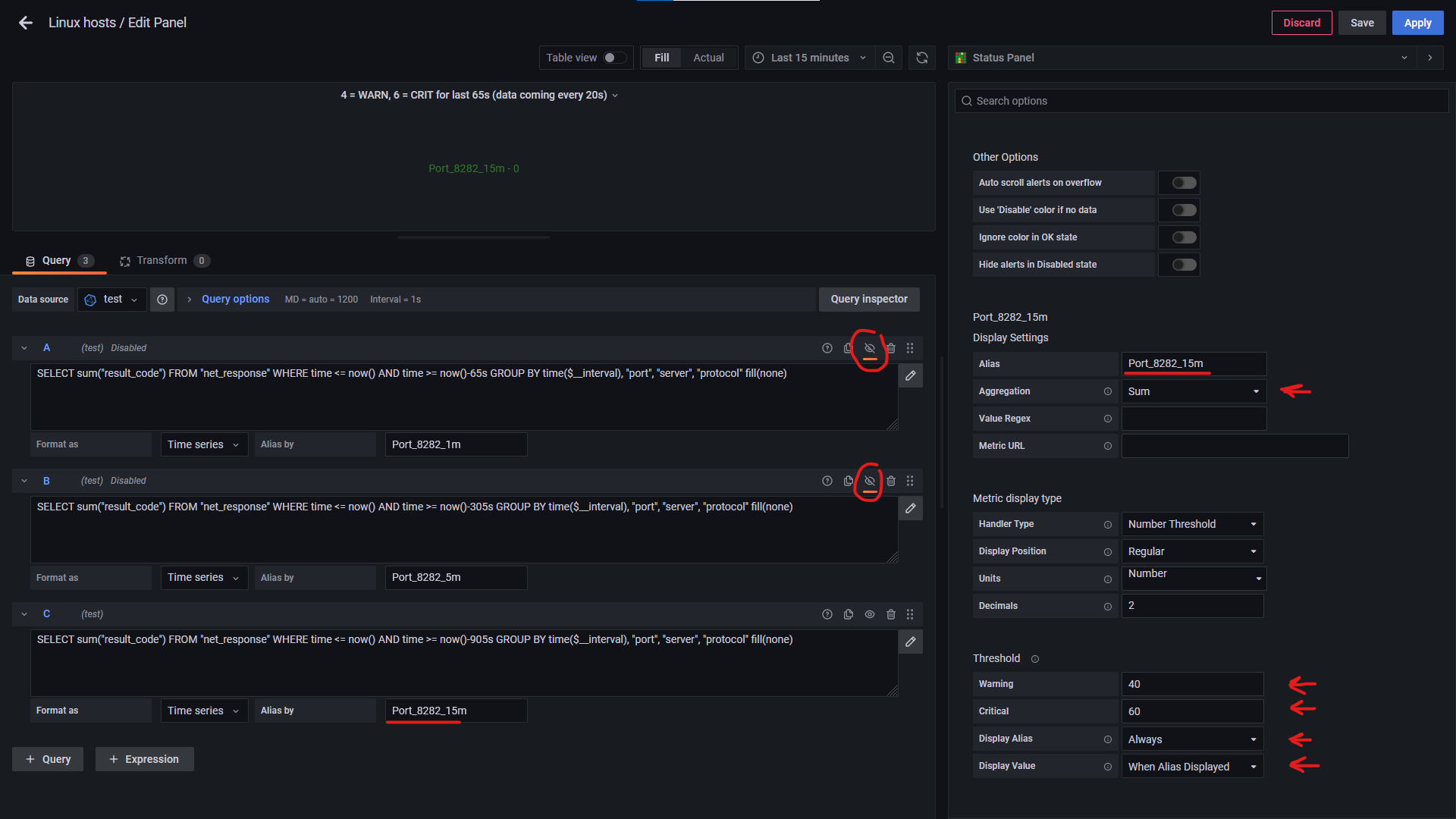
The vonage status plugin seemed to be a good fit for this task. I created three queries:
A: sum_over_time(up{instance=“hostname:9200”}[1m])
B: sum_over_time(up{instance=“hostname:9200”}[5m])
C: sum_over_time(up{instance=“hostname:9200”}[15m])
Thresholds:
A: Warning 2 Critical 0
B: Warning 4 Critical 2
C: Warning 7 Critical 5
For all queries:
Aggregation is Last
Handler Type is Number Threshold
Display Alias is Always True
Display Value is When Alias is Displayed
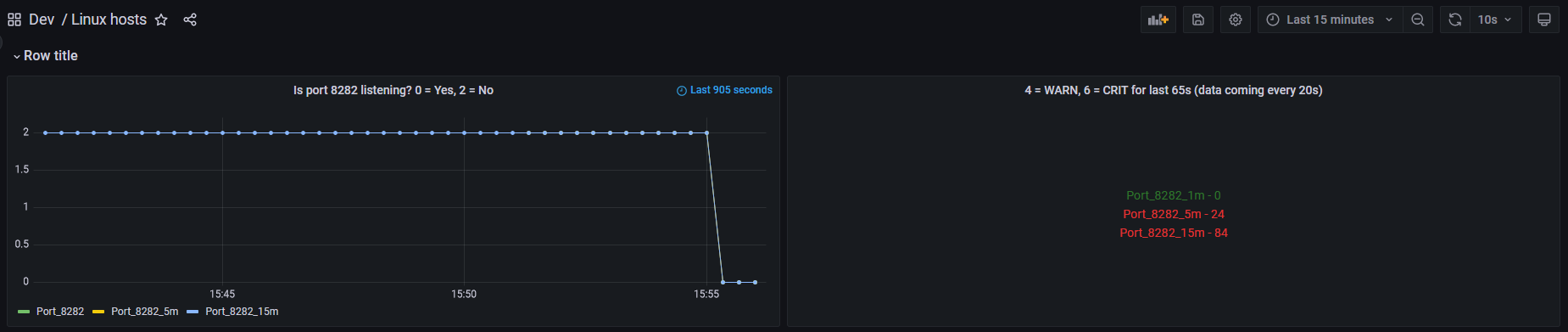
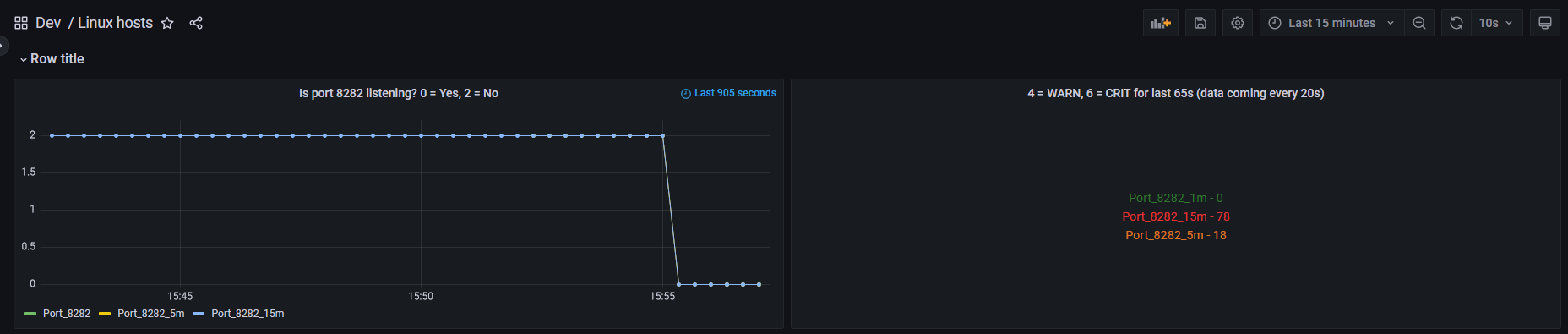
I don’t have any servers with an in-between state, only those who have been reporting up or down for very long periods of time. No matter the server that I put in the query, the status is displayed as green and the value and alias is never displayed. I can verify the queries are returning the expected results by viewing them in Table mode. Servers reporting up show as “1” and servers that are not reporting up show as “0”.
I expected the status box for a server that was “up” to display as green and to show the alias and value. The documentation is not clear for which alias and value it would show, so I expected to discover that by trial and error. I did not expect it to show nothing when every query said to always display the alias.
I reduced the queries to just the following to make it easier to debug:
A: sum_over_time(up{instance=“hostname:9200”}[15m])
It still returned the same results, i.e., the color was always green and no alias or value was displayed.
This is the Grafana log from the moment I hit “Run Queries” to when it stopped writing (edited to remove a few hopefully extraneous lines):
logger=auth t=2023-01-20T17:24:47.815566724Z level=debug msg=“seen token” tokenId=3 userId=1 userAgent=“Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36”
logger=datasources t=2023-01-20T17:24:47.82804432Z level=debug msg=“Querying for data source via SQL store” id=3 orgId=1
logger=query_data t=2023-01-20T17:24:47.828949686Z level=debug msg=“Processing metrics query” query=“unsupported value type”
logger=tsdb.prometheus t=2023-01-20T17:24:47.829916535Z level=debug msg=“Sending query” start=2023-01-20T17:09:47.511Z end=2023-01-20T17:24:47.511Z step=15s query=“sum_over_time(up{instance="hostname:9200"}[15m])”
logger=context userId=1 orgId=1 uname=admin t=2023-01-20T17:24:48.037539615Z level=debug msg=“Updating last user_seen_at” user_id=1
logger=tsdb.prometheus t=2023-01-20T17:24:48.04307898Z level=debug msg=“Sending resource query” URL=api/v1/labels
logger=context userId=1 orgId=1 uname=admin t=2023-01-20T17:24:48.205019479Z level=debug msg=“Updating last user_seen_at” user_id=1
logger=tsdb.prometheus t=2023-01-20T17:24:48.206462678Z level=debug msg=“Sending resource query” URL=“api/v1/label/name/values?start=1674234589&end=1674235489”
The only odd thing in the log is the “unsupported value type” message, but that seems to happen prior to the sending the actual query.
Any help would be appreciated. Thanks.