Hello everyone!
I have very irritating problem with Loki which I assume must be related to misconfiguration. The issue I struggle with is that after some time (usually it is approximately 30 minutes but sometimes it might take a few hours) logs disappear and only the recent ones are returned by the simple ‘take all’ query.
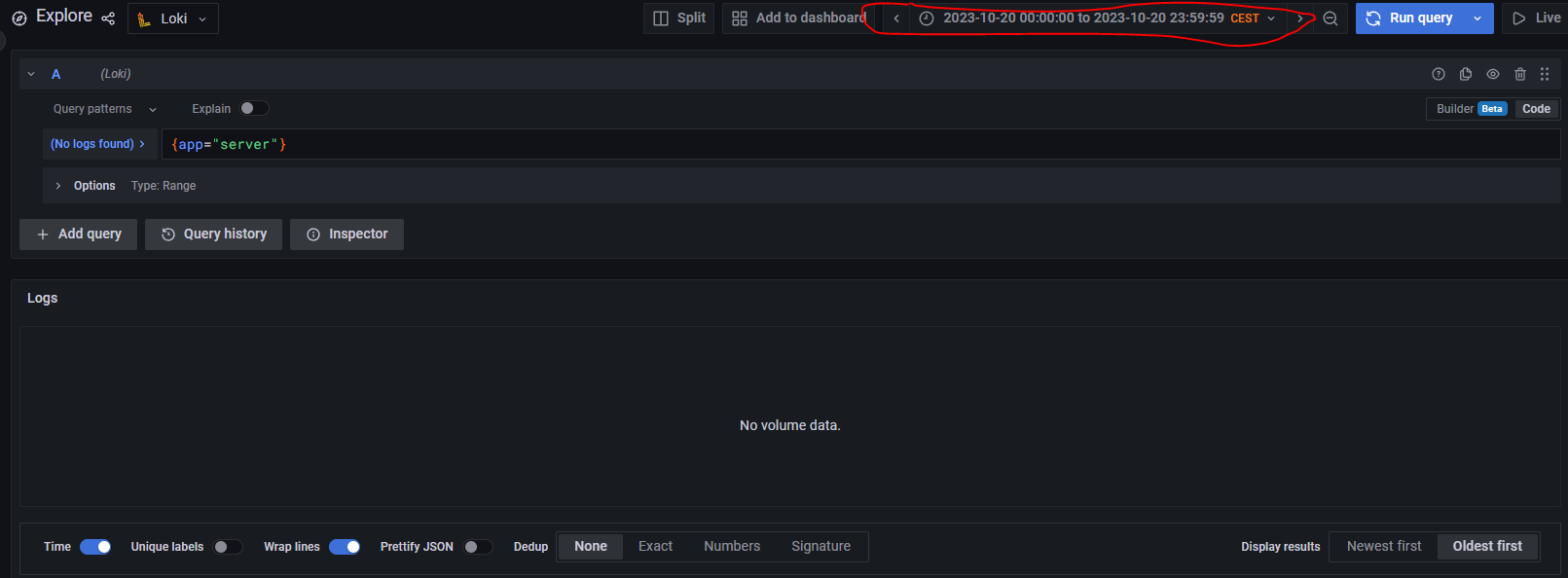
Below is the screenshot of log count chart taken just after loki and promtail initialization:

Following is taken two hours later:

My configuration seems to be quite simple; I have:
- Promtail configured to follow one log file
- Loki in monolithic mode configured to save data using filesystem
Both services are deployed using docker-compose.
Configuration files below (some sensitive data ‘obfuscated’):
docker-compose.yml
version: "3"
networks:
grafana:
external: true
services:
promtail:
image: dvp-docker.tools.finanteq.com/grafana/promtail:2.9.0
privileged: true
userns_mode: host
volumes:
- /var/log/apps:/var/log/apps
- /opt/loki/config:/config
command: -config.file=/config/promtail-config.yml
networks:
- grafana
loki:
image: dvp-docker.tools.finanteq.com/grafana/loki:2.9.0
ports:
- "3100:3100"
volumes:
- /opt/loki/config:/config
command: -config.file=/config/loki-config.yml
networks:
- grafana
promtail-config.yml
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: file_logs
static_configs:
- targets:
- localhost
labels:
app: server
__path__: /var/log/apps/application.log
pipeline_stages:
- match:
selector: '{app="server"}'
stages:
- multiline:
firstline: '^\[\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3}\+\d{2}:\d{2}\]'
max_wait_time: 3s
max_lines: 100000 #single entry can be quite long
- regex:
expression: '^\[(?P<timestamp>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3}\+\d{2}:\d{2})\]\s(?P<level>[A-Z]{4,5})\s\[serverVersion:\s(?P<serverVersion>\d+\.\d+\.\d+(-SNAPSHOT)?)?\] (?P<message>(?s:.*))$' # shortened
- labels: # not all labels
level:
serverVersion:
- template:
source: timestamp
template: '{{ Replace .Value " " "T" 1}}'
- template:
source: timestamp
template: '{{ Replace .Value "," "." 1}}'
- timestamp:
source: timestamp
format: '2006-01-02T15:04:05.999-07:00'
- structured_metadata: # not all metadata
timestamp:
- output:
source: message
loki-config.yml
auth_enabled: false
server:
grpc_server_max_recv_msg_size: 26214400
grpc_server_max_send_msg_size: 26214400
limits_config:
allow_structured_metadata: true
max_line_size: 10kB
max_line_size_truncate: true # for now I'm fine with truncating very big entries
common:
path_prefix: /loki
replication_factor: 1
ring:
kvstore:
store: inmemory
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
storage_config:
tsdb_shipper:
active_index_directory: /loki/tsdb-index
cache_location: /loki/tsdb-cache
shared_store: filesystem
filesystem:
directory: /loki/data
analytics:
reporting_enabled: false
I searched through loki logs but there was really nothing that caught my attention. If you need them, I will gladly attach them.
I would be really grateful if anybody could point what might be the reason for this rather strange behaviour ![]()
Cheers!