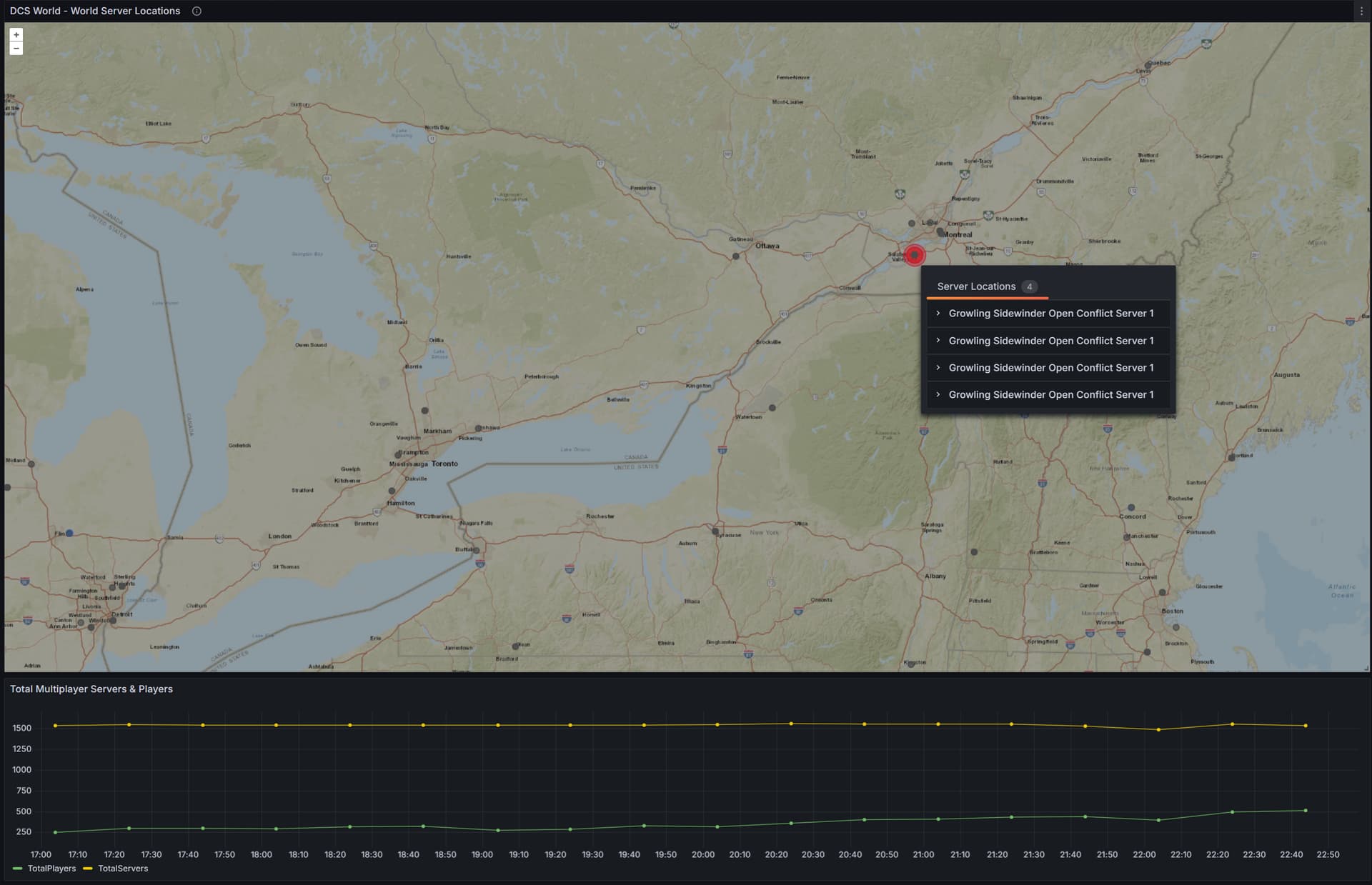
Hi,
I have built a server tracker dashboard that shows all the servers in the world and based on the IP address have added the geo location for each server (location of the IP). I am trying to work out a way to display only the most current result per server. The performance atm is terrible as it does 4 calls per hour on server status (Amount of Players on the server, Mission Name, How long the server has been running etc etc) and there are about 2500 servers. So for each hour I have 10,000 entries to go through. What I would like to know is, Is there a way to define a Unique identifier column and then display only the current value for that server?
Currently I have it hard coded to only display 2500 entries but that is still showing duplicates sometimes. Is there a nice way to do this that wont lead me to recreate my entire influxDB data structure? I will do it if required but I would prefer not to need to do this.
Oh another note, Due to the size (was around 800kb) per data entry, i broke up each server check into individual servers. I guess what I am looking for is a way to just show the latest item using the unique identifier (IP:PORT) for each server.
I am currently seeing this on my map. Picture attached
Are you using flux or influxql?
I think its flux
from(bucket: "ALL-DCS-SERVERS")
|> range(start: -27m)
|> filter(fn: (r) => r["_measurement"] == "SERVER STATS")
|> filter(fn: (r) => r["_field"] == "UID" or r["_field"] == "Lon" or r["_field"] == "Lat" or r["_field"] == "MaxPlayers" or r["_field"] == "Name" or r["_field"] == "Players" or r["_field"] == "Description")
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> group()
|> drop(columns: ["_start", "_stop", "_measurement"])
|> yield(name: "last")
1 Like
what happens if you add
|> group(columns: ["_value"])
|> last()
Blank map
from(bucket: “ALL-DCS-SERVERS”)
|> range(start: -27m)
|> filter(fn: (r) => r[“_measurement”] == “SERVER STATS”)
|> filter(fn: (r) => r[“_field”] == “UID” or r[“_field”] == “Lon” or r[“_field”] == “Lat” or r[“_field”] == “MaxPlayers” or r[“_field”] == “Name” or r[“_field”] == “Players” or r[“_field”] == “Description”)
|> pivot(rowKey:[“_time”], columnKey: [“_field”], valueColumn: “_value”)
|> group(columns: [“_value”])
|> last()
|> drop(columns: [“_start”, “_stop”, “_measurement”])
|> yield(name: “last”)
Also Blank Map
from(bucket: “ALL-DCS-SERVERS”)
|> range(start: -27m)
|> filter(fn: (r) => r[“_measurement”] == “SERVER STATS”)
|> group(columns: [“_value”])
|> last()
what does that mean, use full sentences please. your issue is more flux query than grafana best to post here
please share your data view to see which “column” or data point causes the duplicates? is it the time field?