Hi Team,
Please see the below Grafana error on the topic of InfluxQL vs FLUX.
Error:
A query returned too many datapoints and the results have been truncated at 15511 points to prevent memory issues. At the current graph size, Grafana can only draw 1551. Try using the aggregateWindow() function in your query to reduce the number of points returned.
Dashboard using Flux query language

I do not see this error when I used InfluxQL as language type
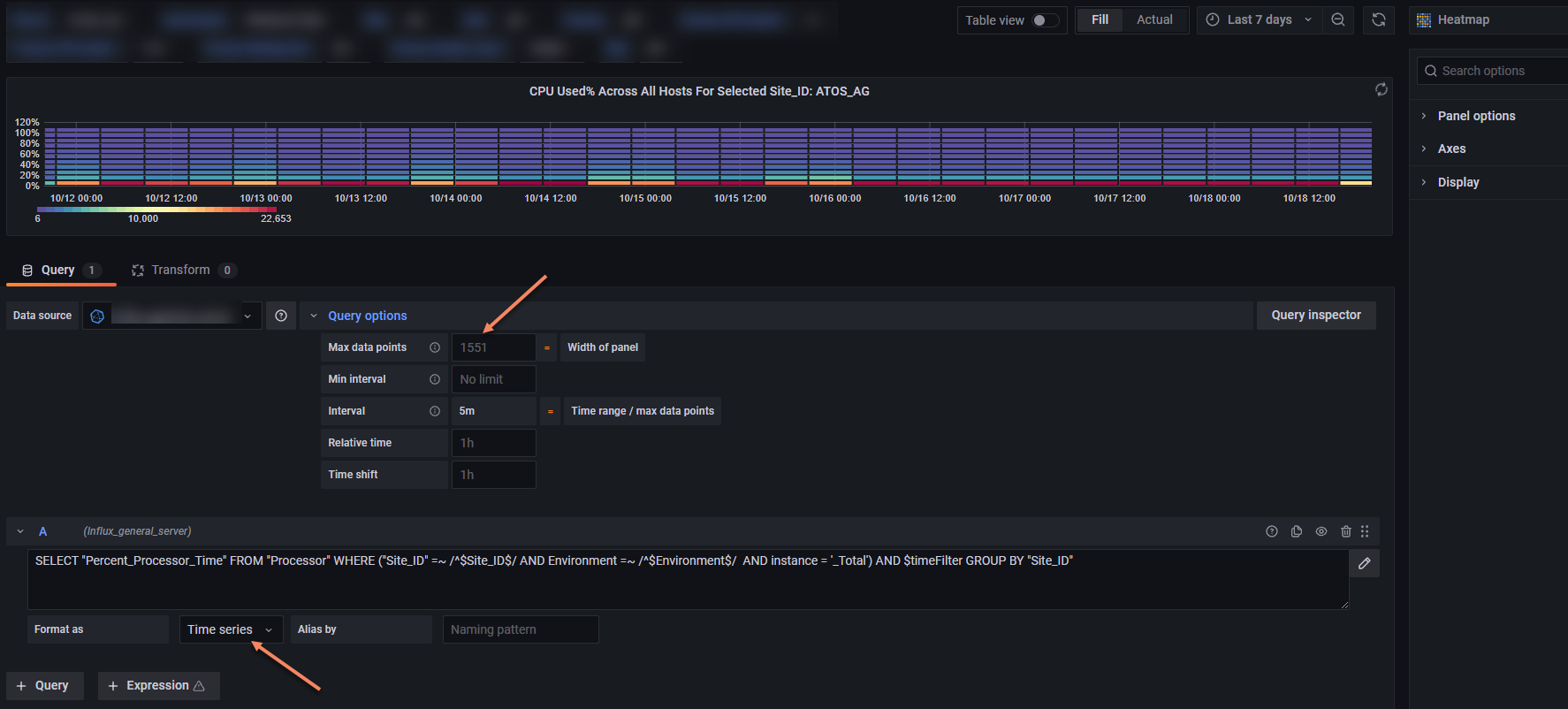
InfluxQL:
SELECT “Percent_Processor_Time” FROM “Processor” WHERE (“Site_ID” =~ /^$Site_ID$/ AND Environment =~ /^$Environment$/ AND instance = ‘_Total’) AND $timeFilter GROUP BY “Site_ID”
One is Flux another is InfluxQL and it pulls equal number of datapoints, while flux throws this error InfluxQL does not.
@davidharris @grant2 @usman.ahmad tagging for attention please ![]()
NB. This was asked before but didn’t recieve any attention hence raising again: Error: A query returned too many datapoints and the results have been truncated