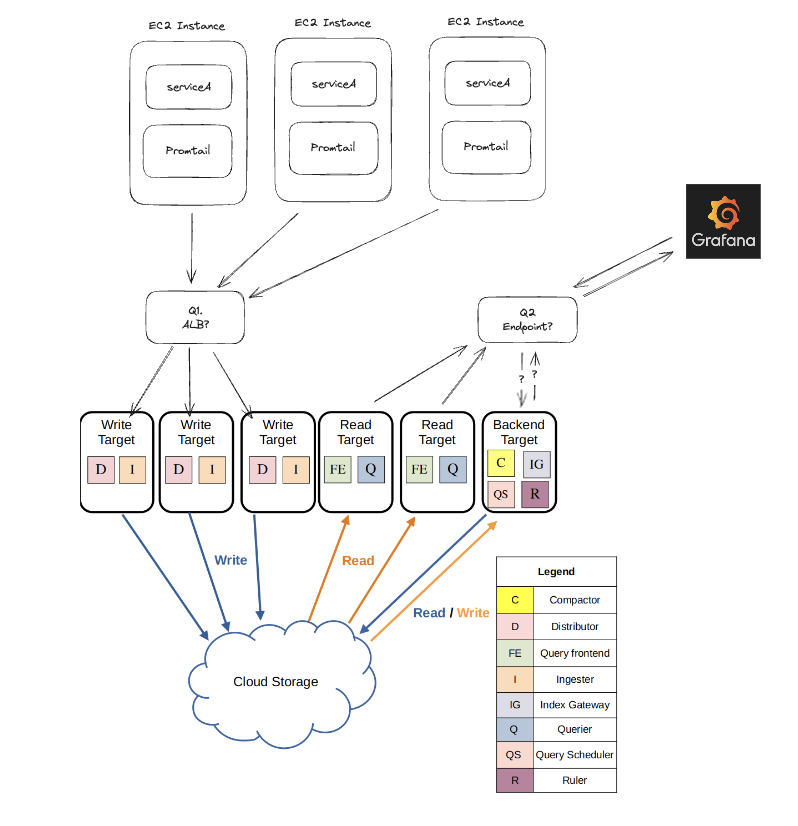
I am trying to set up a Loki cluster in an AWS EC2 environment and intend to use ALB and NLB for load balancing. I have configured the ring using Consul and am currently testing with just two instances. I have some questions based on the attached image:
Looking at the Consul KVStore, it seems that both instances are registered as Distributor and Compator respectively, suggesting that one is a reader and the other is a writer. Is this interpretation correct?
If I want multiple services to send logs to Loki via Promtail, it seems logical to have a single endpoint for load balancing. Can I achieve this with ALB? Alternatively, does Loki itself have logic for load distribution? For example, if there are Loki1, Loki2, and Loki3 instances, and Loki1 receives a lot of write requests, does Loki automatically distribute them across Loki2 and Loki3?
Similarly, for distributing queries from Grafana to readers, it seems necessary for something to split and merge queries. Can any Loki instance be specified, and will the cluster handle this automatically?
Please correct me if I have misunderstood anything.
As I am setting up without using Kubernetes, there are limited resources available for reference. That’s why I’m reaching out with these questions.
This is a rather big question, I’ll try to answer with as much detail as I can. I happen to be running Loki with ECS as well, so if you have any additional question let me know I should be able to help.
If you have a relative big log volume (say more than 200GB a day) I would recommend you to run Loki with Simple Scalable Mode. Otherwise you can run monolithic mode.
When running in monolithic mode, every Loki container you run will have every component. As such your ALB should be configured to distribute traffic to all containers evenly from a frontend perspective.
I would also recommend you to use different Configuration Template for write and read/backend containers. You need persistent volumes for write component, and the easiest way to do that is to mount a volume from host into write container (because ECS doesn’t have persistent volume). And by separating write and read/backend you can scale them separately more easily.
While trying various methods, I found that separating write and read traffic through nlb and directing them to the writer cluster and reader cluster, respectively, works properly. I haven’t run the backend service, so the query frontend may not work, but as of now, the performance is satisfactory.
The official documentation mentioned setting up a reverse proxy, but it seems I missed that part. Anyway, I hope this information is helpful to others.