Sure!
^^ Visualised based off of the queries you provided for me, basically the exact same setup.
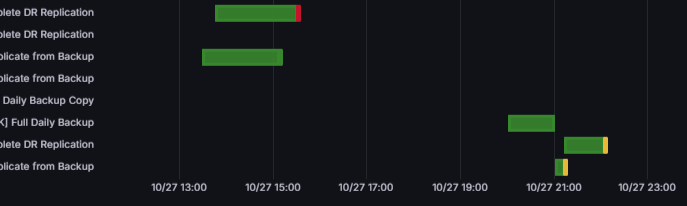
For the top rop visible, the first task block resulted in a failure, so correctly is red, but the second time only resulted in a warning. Failure process returns are 2, while warnings are 1, so the max_over_time query that gives the block colour is setting the colour/value of both blocks to 2/Fail.
I have metrics:
v_job_general_last_result{instance=“myInstance.local:9182”,job=“Insights”,scheduled=“true”}, jobName is my unique label per task, which is what your ‘type’ example represented. There are 10-15 different tasks that all provide the above metric, so while running, the metrics available would be:
-
v_job_general_last_result{instance=“myInstance.local:9182”,job=“Insights”,scheduled=“true”,jobName=“TestJob1”} -1
-
v_job_general_last_result{instance=“myInstance.local:9182”,job=“Insights”,scheduled=“true”,jobName=“TestJob2”} -1
-
v_job_general_last_result{instance=“myInstance.local:9182”,job=“Insights”,scheduled=“true”,jobName=“TestJob3”} -1
Then, at a point in time when they have all finished running:
-
v_job_general_last_result{instance=“myInstance.local:9182”,job=“Insights”,scheduled=“true”,jobName=“TestJob1”} 0
^^ Job success
-
v_job_general_last_result{instance=“myInstance.local:9182”,job=“Insights”,scheduled=“true”,jobName=“TestJob1”} 1
^^ Job complete with warning
-
v_job_general_last_result{instance=“myInstance.local:9182”,job=“Insights”,scheduled=“true”,jobName=“TestJob1”} 2
^^ Job failed
One minute after the job has completed; the file containing the metric is removed, so the Last value of the metric is the final status of the task.
The dificulty is the tasks all run on a different schedule, some run every 4 hours, some every 12, some every 24 etc. I want this visualsation to be able to show me the last weeks worth of results, using the State Timeline visualisation to give a rough indication of the job duration too (the amount of time the metric is available for roughly fills this purpose, the blocks in the orignal screenshot are fine to indivation a rough duration, although that’'s more of a nice to have than essential)
This is an alternative visualisation i made before, but the status of the task is only represented at the end of the block:
Which isn’t as clear as colouring the whole block of each run.
The metrics are created from powershell by me, so i can be reasonable flexible in what i provide and when, currently also providing start and end times in epoch for each job for example, in the similar format:v_job_general_last_start{instance=“myInstance.local:9182”,job=“Insights”,scheduled=“true”,jobName=“TestJob1”} 123456789 (obviously not a real epoch time but you get the point)