What Grafana version and what operating system are you using?
We are using Grafana 9.4.3
What are you trying to achieve?
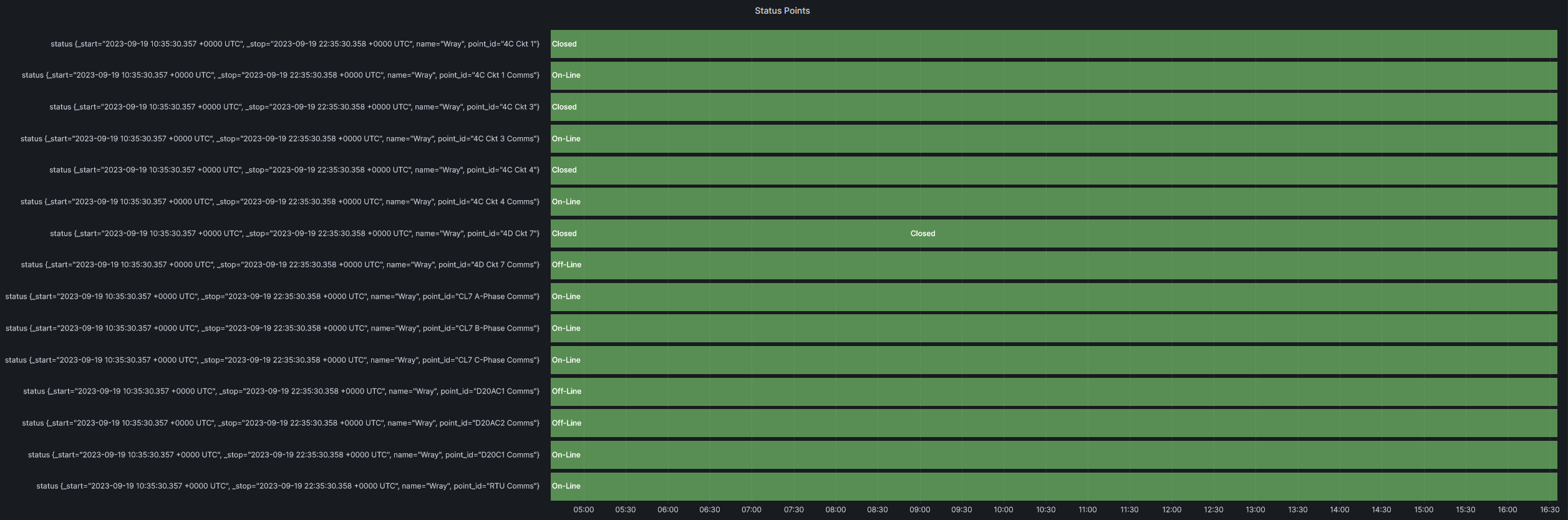
We have an InfluxDB with a number of data points being fed to it from our SCADA system. We’ve gotten analog values to show up quite nicely, but now we’re trying to get some status points to show up on a dashboard. We would like to use a State Timeline panel on a dashboard to display the status of these points over time, being as Grafana is going to be our more historical viewer where as our SCADA system itself is what we’ll use for real-time data.
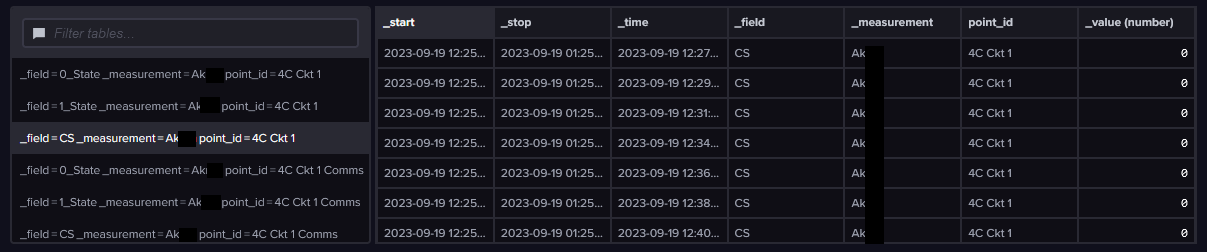
I am sending status points through from SCADA with each station being a measurement, the particular data point I’m looking at being set up as the tag, and the data value as well as a number of other attributes that go along with that data point being sent through as fields. Of key importance here are the CS, 0_State, and 1_State fields. CS contains the current state of the data point and is an integer 0 or 1, 0_State contains a user-friendly term describing what the status of the point is when its CS is 0, and 1_State contains a user-friendly term describing what the status of the point is when its CS is 1. These are all sent through from the SCADA system every time for two reasons: (1) so that any changes to the configuration of the point in our SCADA system is seamless on the historical database stored in InfluxDB and viewed in Grafana, and (2) so that we can re-use a lot of alarm processing and logic in Grafana and any other scripting we do to take the data from InfluxDB, regardless of what the data point is…we can just use CS as a 0 or 1 (together with another AS/Abnormal State field that tells us which state is bad but is not important to this question). A small snipped of this data is shown here, together with an unlabeled view of a panel:
How are you trying to achieve it?
I have tried flux queries where I try pulling the three fields in question and using some conditional logic inside a map function to try to assign the values in the 0_State or 1_State fields either into the CS field or into a new column based on the value in the CS field. I have looked through and played with almost all of the transforms in Grafana to see if I could build it from there, and I can’t figure out any of them. The closest flux query that I’ve gotten is here:
from(bucket: "SCADA")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "Akron")
|> filter(fn: (r) => r["point_id"] == "4C Ckt 1" or r["point_id"] == "4C Ckt 1 Comms" or r["point_id"] == "4C Ckt 3" or r["point_id"] == "4C Ckt 2" or r["point_id"] == "4C Ckt 2 Comms" or r["point_id"] == "4C Ckt 3 Comms" or r["point_id"] == "4C Ckt 5" or r["point_id"] == "4C Ckt 5 Comms" or r["point_id"] == "4C Ckt 7" or r["point_id"] == "4C Ckt 7 Comms" or r["point_id"] == "4C Ckt 8" or r["point_id"] == "4C Ckt 8 Comms" or r["point_id"] == "D20AC1 Comms" or r["point_id"] == "D20AC2 Comms" or r["point_id"] == "D20C1 Comms" or r["point_id"] == "MJX A-Phase Comms" or r["point_id"] == "MJX B-Phase Comms" or r["point_id"] == "MJX C-Phase Comms" or r["point_id"] == "RTU Comms" or r["point_id"] == "WAPA RTU Comms")
|> filter(fn: (r) => r["_field"] == "CS")
|> map(
fn: (r) => ({ r with
status: if r.CS == 0 then string(v: r["0_State"]) else string(v: r["1_State"]),
}),
)
What happened?
With the map function and conditional logic in the flux query, I get nothing at all, I get an empty column with no data in it, or I get myriad different errors. With the transforms, I haven’t gotten anything meaningful to happen. The query above just gives me an empty Status value in each data point’s record.
What did you expect to happen?
I would like the panel above to show up about how it is now, except that instead of 0 and 1 for the values, it should contain whatever is in 0_State or 1_State for each data point (On-line, Off-line, Tripped, Closed, Normal, Failed, etc.)
Any help on this would be much appreciated. I figure that there has got to be a way to do this and it probably isn’t all that terribly hard, but I just can’t figure it out.
Let’s forget about Grafana for a bit and focus only on getting the data to appear correctly in Influx Data Explorer. In your above statement about getting nothing at all, are you saying that this query in Influx Data Explorer gives you no data (but also, no errors)?
from(bucket: "SCADA")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "Akron")
|> filter(fn: (r) => r["point_id"] == "4C Ckt 1" or r["point_id"] == "4C Ckt 1 Comms" or r["point_id"] == "4C Ckt 3" or r["point_id"] == "4C Ckt 2" or r["point_id"] == "4C Ckt 2 Comms" or r["point_id"] == "4C Ckt 3 Comms" or r["point_id"] == "4C Ckt 5" or r["point_id"] == "4C Ckt 5 Comms" or r["point_id"] == "4C Ckt 7" or r["point_id"] == "4C Ckt 7 Comms" or r["point_id"] == "4C Ckt 8" or r["point_id"] == "4C Ckt 8 Comms" or r["point_id"] == "D20AC1 Comms" or r["point_id"] == "D20AC2 Comms" or r["point_id"] == "D20C1 Comms" or r["point_id"] == "MJX A-Phase Comms" or r["point_id"] == "MJX B-Phase Comms" or r["point_id"] == "MJX C-Phase Comms" or r["point_id"] == "RTU Comms" or r["point_id"] == "WAPA RTU Comms")
|> filter(fn: (r) => r["_field"] == "CS")
|> map(
fn: (r) => ({ r with
status: if r.CS == 0 then string(v: r["0_State"]) else string(v: r["1_State"]),
}),
)
Hi grant2, thanks for the reply. I worded my statement poorly. And, I see that I didn’t copy the correct query in quite right, either, but it doesn’t end up changing my result very much.
This query:
from(bucket: "SCADA")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "Ak")
|> filter(fn: (r) => r["point_id"] == "4C Ckt 1" or r["point_id"] == "4C Ckt 1 Comms" or r["point_id"] == "4C Ckt 3" or r["point_id"] == "4C Ckt 2" or r["point_id"] == "4C Ckt 2 Comms" or r["point_id"] == "4C Ckt 3 Comms" or r["point_id"] == "4C Ckt 5" or r["point_id"] == "4C Ckt 5 Comms" or r["point_id"] == "4C Ckt 7" or r["point_id"] == "4C Ckt 7 Comms" or r["point_id"] == "4C Ckt 8" or r["point_id"] == "4C Ckt 8 Comms" or r["point_id"] == "D20AC1 Comms" or r["point_id"] == "D20AC2 Comms" or r["point_id"] == "D20C1 Comms" or r["point_id"] == "MJX A-Phase Comms" or r["point_id"] == "MJX B-Phase Comms" or r["point_id"] == "MJX C-Phase Comms" or r["point_id"] == "RTU Comms" or r["point_id"] == "WAPA RTU Comms")
|> filter(fn: (r) => r["_field"] == "CS" or r["_field"] == "1_State" or r["_field"] == "0_State")
|> map(
fn: (r) => ({ r with
status: if r.CS == 0 then string(v: r["0_State"]) else string(v: r["1_State"]),
}),
)
gives me all of my original data, just like I would have gotten without the map function in it at all, except that I now have an empty status column in each “table” (each combination of _measurement, point_id, and _field). So, what I should have said is that, other than inserting an empty column into the data I was getting before, the addition of the map function does nothing.
In theory, it seems like I have all of the data that I should need coming through the flux query, whether just in InfluxDB’s Data Explorer or in Grafana. I just can’t get it to all go where I need it to show up.
However, if I change r._value to r.CS in the if statement, then I get the status column filled with false, except that it is in all cases…even when the _value of CS is 0
Could you remove (for the moment) the map function and then share a screenshot from Influx Data Explorer of the query output? Basically wanting to see all the fieldnames and values for a few rows of data.
With the toInt() function in there, I get a new error:
runtime error @6:6-6:13: toInt: failed to evaluate map function: cannot convert string "Closed" to int due to invalid syntax
I’m guessing it doesn’t like that my 0_State and 1_State field values are strings when I use toInt(), and it doesn’t like that my CS field value is an integer when I don’t use toInt().
The pivot() function got everything into a single table per “point_id”, which is perfect, but now the conditional part of the map function is not working. Incidentally, if I substitute “true” and “false” above with r[“0_State”] and r[“1_State”], respectively, it does put the values from these two columns into the status column. But, for right now, I am getting the false evaluation regardless of whether the CS column is 1 or 0.
from(bucket: "SCADA")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "Akron")
|> filter(fn: (r) => r["point_id"] == "4C Ckt 1" or r["point_id"] == "4C Ckt 1 Comms" or r["point_id"] == "4C Ckt 3" or r["point_id"] == "4C Ckt 2" or r["point_id"] == "4C Ckt 2 Comms" or r["point_id"] == "4C Ckt 3 Comms" or r["point_id"] == "4C Ckt 5" or r["point_id"] == "4C Ckt 5 Comms" or r["point_id"] == "4C Ckt 7" or r["point_id"] == "4C Ckt 7 Comms" or r["point_id"] == "4C Ckt 8" or r["point_id"] == "4C Ckt 8 Comms" or r["point_id"] == "D20AC1 Comms" or r["point_id"] == "D20AC2 Comms" or r["point_id"] == "D20C1 Comms" or r["point_id"] == "MJX A-Phase Comms" or r["point_id"] == "MJX B-Phase Comms" or r["point_id"] == "MJX C-Phase Comms" or r["point_id"] == "RTU Comms" or r["point_id"] == "WAPA RTU Comms")
|> filter(fn: (r) => r["_field"] == "CS" or r["_field"] == "1_State" or r["_field"] == "0_State")
|> toString()
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value" )
|> map(fn: (r) => ({ r with status: if r.CS == "0" then
r["0_State"]
else
r["1_State"],
}),
)
returns the value of the 0_State column in status when the value of the CS column is 0, and it returns the value of the 1_State column in status when the value of the CS column is 1.
Now, I have a minor problem with my data panel. Here is what I started with when I couldn’t get everything joined up in the query:
Okay, once I applied the query above, I was able to apply a Filter by name Transform and use a regex of: ^(_time|status).*
to get the number of fields down to one per record instead of that huge jumble. I guess my only issue now is that the labels for the name of each series keep going to a crazy long expression every time the dashboard updates, and I can’t seem to get overrides to stick to them because the names include the time period being looked at, so they change every time.
I tried using the Rename by regex Transformation with the following RegEx string: .+point_id\="(.*?)".+
and it made no difference. I could really live with just the contents of the point_id being the series name. regex101.com set to Golang seems to like that string:
but the series names aren’t taking it.
I figured out in a second copy of this panel how I can go in and individually rename each series using overrides with Field with Name Matching by Regex
but that is a fairly manually-intensive process to set up, and it would be a lot nicer if I could just use a transformation or something similar to do it to all of my series. Am I asking too much on that (and it’s fair if I am…I’m still learning what all can and can’t be easily done with InfluxDB and Grafana, and I’m only about a week in), or is there another simple or elegant solution that I’m just overlooking?
OK, so I think this is turning into a Regex challenge. Am sure there is a solution using Rename by Regex. However, maybe (and this is a long shot) these 2 transformations will work?
Well, the Partition by Values transform didn’t work…it just told me that you can’t do that with a single frame. But, with the drop function in my query, I realized that the overrides for each series are a lot easier because they at least have static names now, so those become quite a lot simpler to set up.
That being said, I think I can live with this now. Thank you so much for your help!