I have 3 cassandra servers, installed JMX javaagent on cassandra .
Im using prometheus as datasource and added below line in cassandra-env.sh
JVM_OPTS=“$JVM_OPTS -javaagent:/etc/cassandra/jmx_prometheus_javaagent-0.10.jar=7070:/etc/cassandra/cassandra.yml”
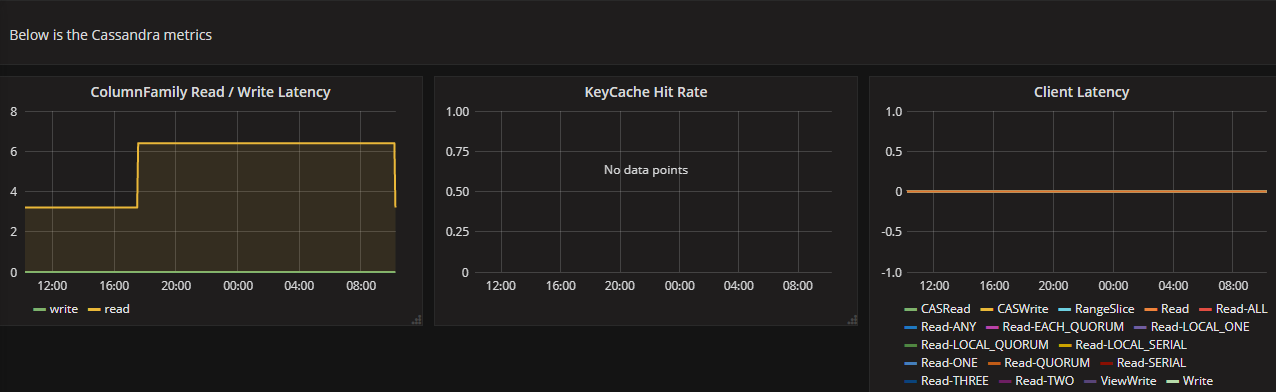
Also imported cassandra detail dashboard.
Data is populating but not able to choose those 3 servers in dashboard.
Could you please help me
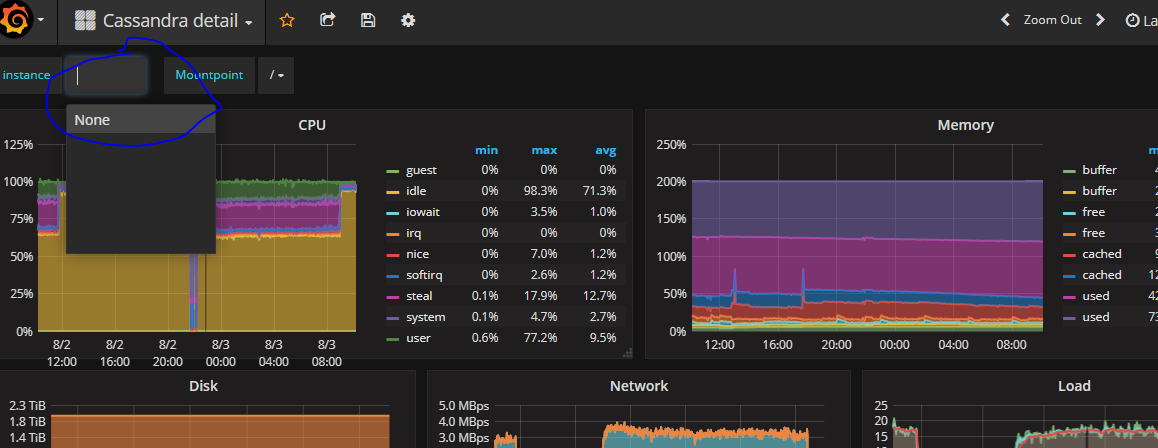
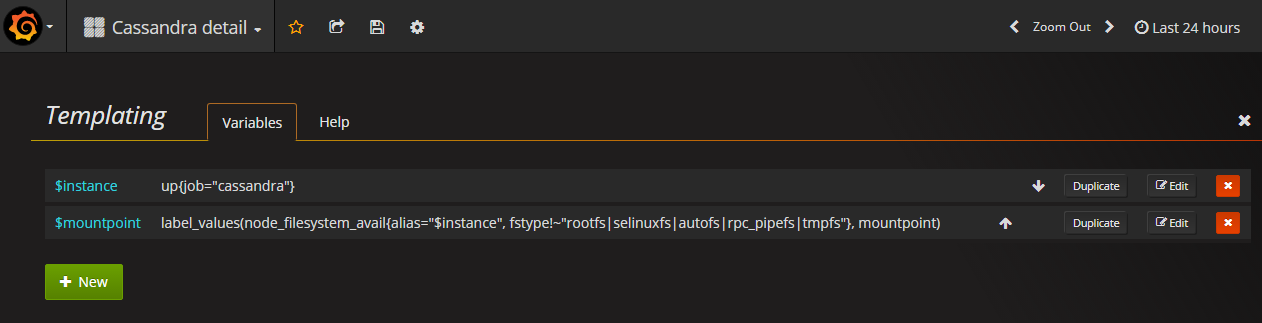
What does the query for the instance query variable look like? (You can find it by clicking on the cog wheel icon and then on “Templating”)
daniellee Please update on this
If you click on Edit, does the query return any values in the preview of values section (or does it say none?):
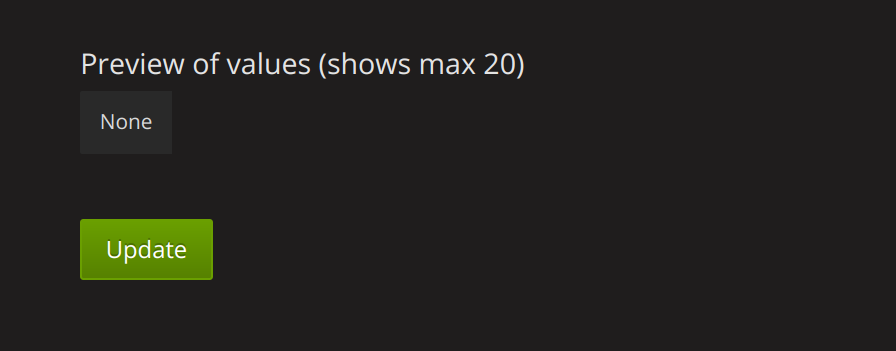
I think the problem is that you do not have any data for Cassandra jobs that are up.
Whenever Prometheus scrapes a target, it stores a synthetic sample with the metric name up and the job and instance labels of the scraped instance. If the scrape was successful, the value of the sample is set to 1. It is set to 0 if the scrape fails. Thus, we can easily query which instances are currently “up” or “down”
If execute the query: up instead of up{job="cassandra"} does it return anything? Is your prometheus working?

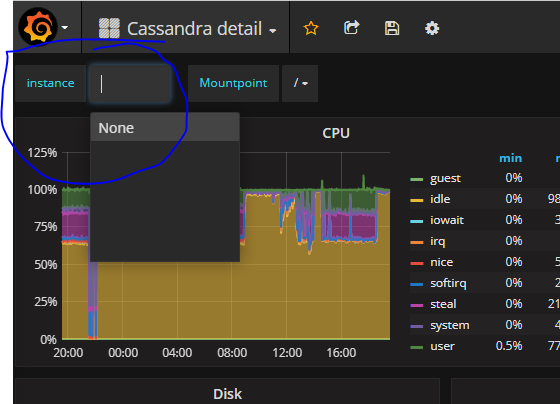
Did you try running the query: up
This is a problem of missing data - that is the reason for your dropdown not having any values.

Aha, you missed telling me an important detail. There is a regex for extracting the alias that might be incorrect. It expects there to be an alias label.

As I don’t have the data for Cassandra, I’m not sure what the regex should be. If you just remove the regex, what preview values do you get for the query: up{job="cassandra"}?
As an example, I tested the query: up{job="prometheus"} and got the following:

And to get the value of the instance label, I changed the regex to: /.*{instance="(.*)",job.*/

The templating error is expected - the value returned is not a valid value.
There is no alias label so try using the instance label instead maybe? You can change the regex to the one I tested above:


Actually this is probably better, it excludes the port:
/.*{instance="(.*):[0-9]{4}.*/
You are missing a character in the regex, quoting in Discourse removed it for some reason…
should be /.*{instance="(.*)",job.*/.
But try /.*{instance="(.*):[0-9]{4}.*/ instead to exclude the port.


It would seem the query for the Mountpoint template variable expects an alias label as well:
label_values(node_filesystem_avail{alias="$instance", fstype!~"rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs"}, mountpoint)
I don’t know what it should be but have you tried changing alias to instance?
EDIT: also I’m not sure if the instance variable should include the port or not. So try with both the port and without the port. Here is a shorter regex for instance with port: /.*{instance="(.*)",.*/
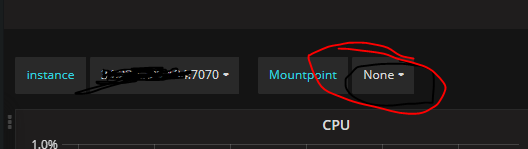


It still has label alias= in the query?
To learn more about PromQL start here:
Don’t know if you are still stuck but the query is incorrect. alias="$instance" should be instance="instance".
And looking at my prometheus data, the $instance variable should probably include the port.
I know this is a very old thread but I happened upon it while searching for this exact same problem so I figured I’d save someone else the time.
In my case the issue stems from the fact that my Cassandra cluster and node-exporter services are built via docker-compose which means they each get their own unique server IP on swarm’s overlay network. Thus far I have not found a way using stacks to correlate the underlying host.
Raw Prometheus data for my Cassandra cluster looks like this:
up{host=“node00”,instance=“cassandra-00:7400”,job=“cassandra”} 1
(I added the host label inside my prometheus.yml in an attempt to bridge the gap to no avail)
IP address for this host:
/prometheus # ping -c 1 cassandra-00
PING cassandra-00 (10.0.47.205): 56 data bytes
64 bytes from 10.0.47.205: seq=0 ttl=64 time=0.083 ms
The raw prometheus data for one of my node-exporter mounts looks like this:
node_filesystem_avail{device="/dev/sda2",fstype=“xfs”,instance=“10.0.47.235:9100”,job=“node-exporter”,mountpoint="/rootfs"}
The IPs for the instance, while on the same network, are different because each instance of each service gets its own IP. There is no correlation.
If I were to install Cassandra and node-exporter as a systemd services I could use the shared hostname/IP address and this dashboard would work exactly as expected.
From my research, unless there is a better way to tie the different IPs given to each service, this dashboard simply won’t work in a docker swarm cluster stack using docker-compose.
If anyone has any ideas about that (maybe a rewrite of the target would work) I’d love to hear about it.