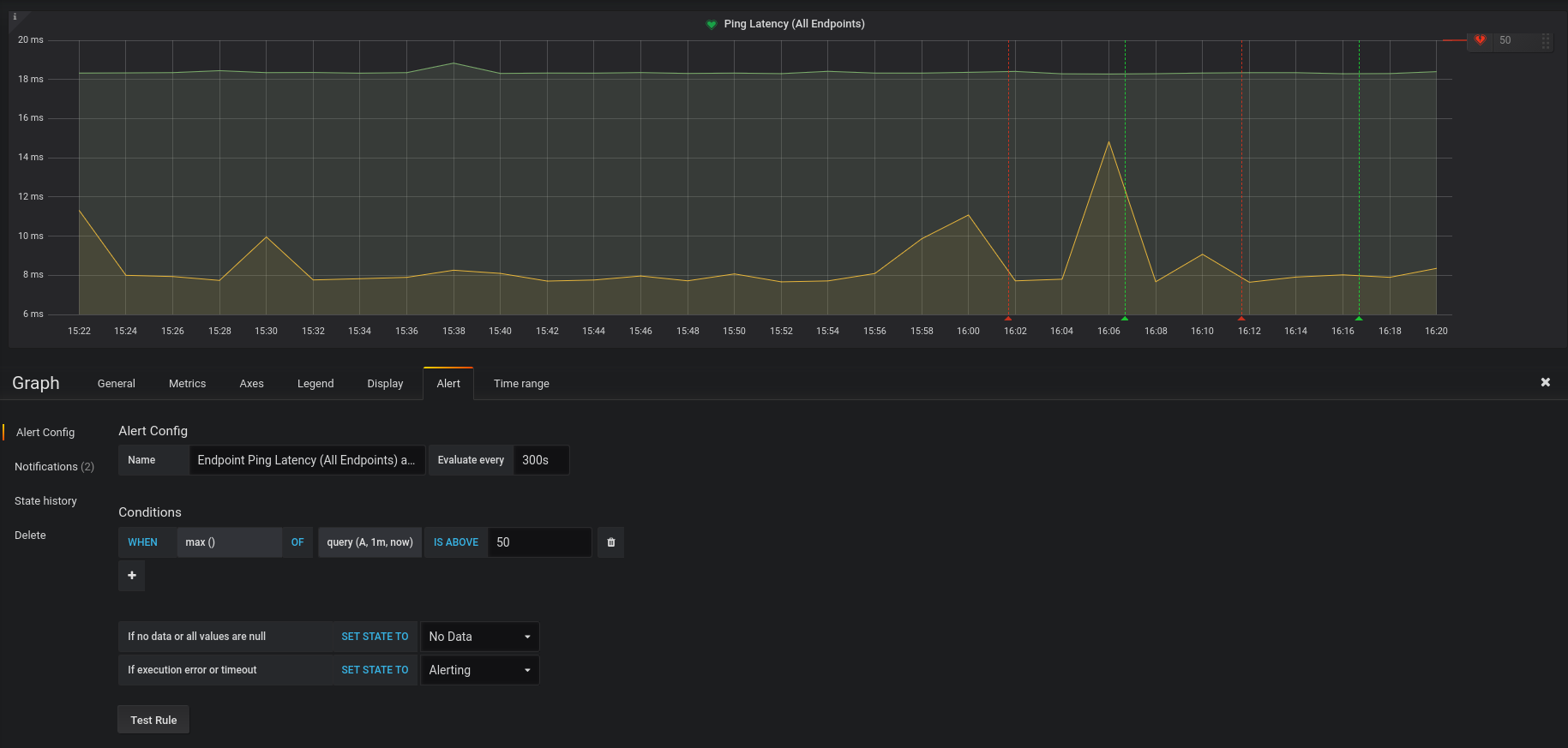
With the default settings, it’s picked up our endpoints just fine. But as soon as I enable alerting, we get alternating check pass/fails (basically; OK, fail, OK, fail, OK, fail). See attached screenshot.
The error we get is:
Error: tsdb.HandleRequest() error Request failed status: 500 Internal Server Error
As this is all Grafana hosted, we’re at the mercy of whoever is managing the environment. Are there any issues?
Hi Andy,
yes. there seems to be a bug in our backend which affects queries that have a short timeframe compared to the data resolution (in your case, the alert query queries for 1minute of data but the data resolution is 2 minutes).
Can you try making your alert query for a longer timeframe such as 3 minutes?
In the meantime I’ll keep working on this bug.