Hi folks – I’m trying to debug a loki query timeout for a deployment I’m running. The query makes it to loki just fine, but times out after 60s. Here’s a trace for the query which is failing:
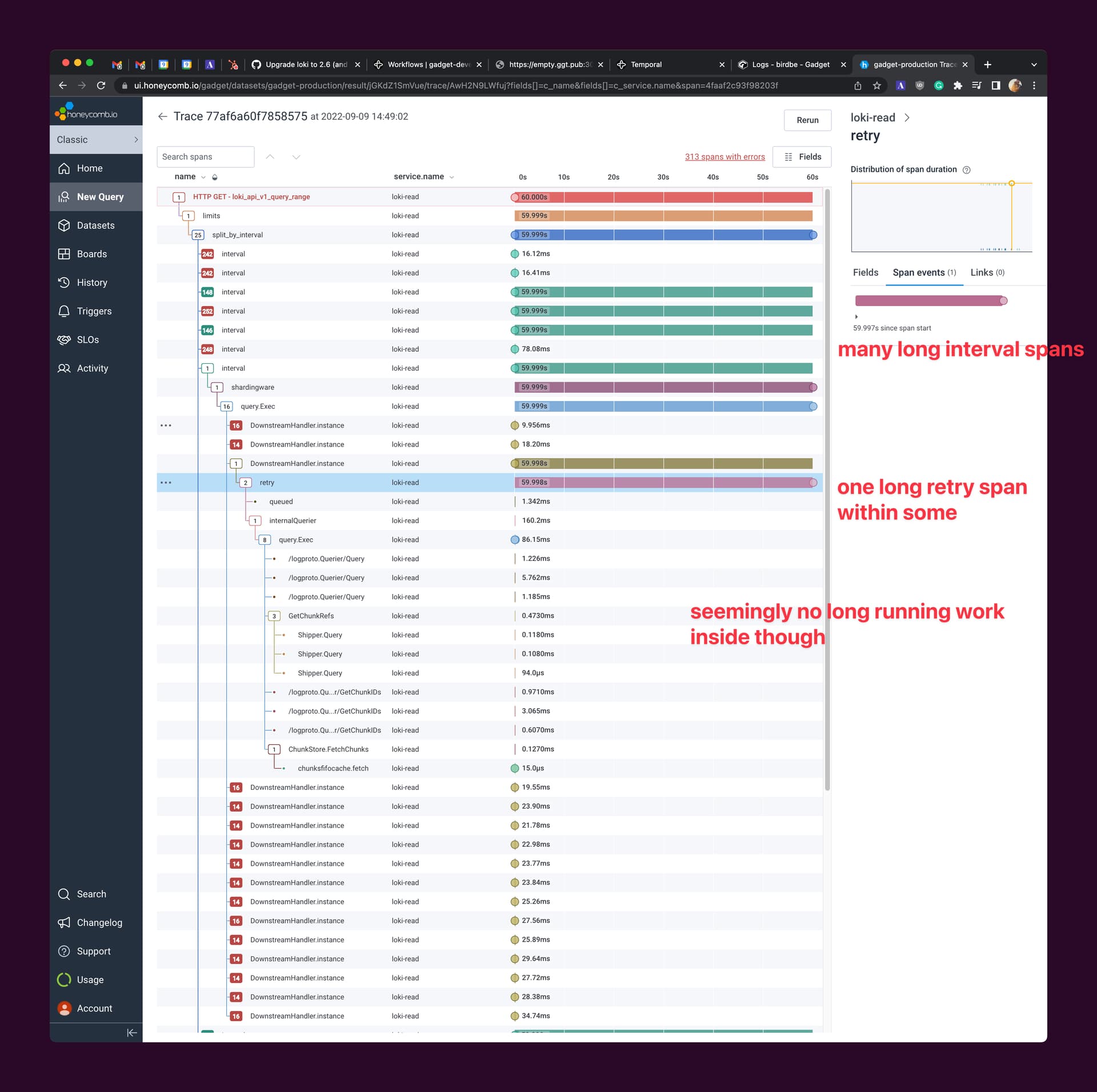
Here’s the details:
- we’re running loki 2.6 in k8s using the simple-scalable helm chart with 5 read replicas
- we’re using GCS for storage and boltdb-shipper for index storage
- the query is over a 6 hour time range
- the log volume is substantial but not huge (like 10GB of logs)
- this is the query:
{app_logs_service=~".+", environment_id="5343"} | json | userspaceLogLevel>=30 | connectionSyncId = "96" - the same query works over a much shorter time range
- I don’t see any errors in the logs surrounding the underlying store’s rate limits or something like that (no 429s from GCP I can spot)
- It seems like sometimes restarting the loki pods fixes queries, but doesn’t other times.
Can anyone see what might be happening within that trace that would explain this timeout pattern? Or can I provide any more info that might illuminate the issue?