Hi, I’m new to Loki, It is pretty good and solves many of my problems. But sometimes I face issues that logs seem to be like loss in some period. I config to store data chunks in s3, and also have WAL configured.
I’ve seen a few threads on the forum with similar issue. If you are using multiple writer instances, your problem is most likely in the ring membership. Please share your configuration and an output of the /ring output.
The problem seems to be fixed when I apply your suggestion
querier:
query_ingesters_within: 2h
I will observe it.
Could I ask another question, I also use Loki stack with a single pod and see it consumes about a maximum of 1GB and 100 millicores, but its query speed is not different from Loki’s simple scalable deployment mode with Loki read, write, and backend separately that use about 2-3GB and 800 millicores. Do you have any best practices for enhancing query speed for this deployment mode?
If you are running in simple scalable mode, make sure query frontend is enabled, and you are splitting queries in a reasonable time frame. Unless you have really heavy log volume, I find that splitting queries by 30-minute is usually reasonable.
Also keep in mind a lot of performance gain for Loki comes from distribution, as a result if you don’t have adequate amount of logs you likely won’t get much performance gain out of running in simple scalable mode. Personally our Loki cluster with 4 readers can achieve roughly 5GB per second read performance, I know there are others with bigger cluster with a lot higher number.
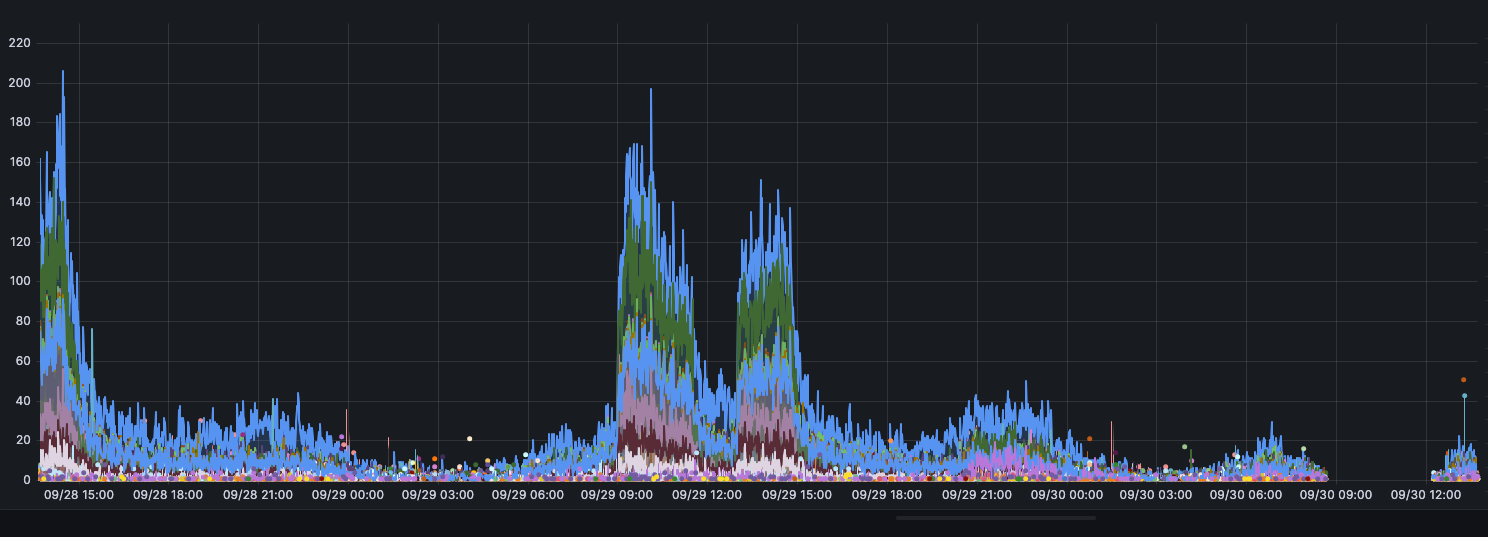
Today this error came back, I queried all containers, and they were lost data from 7h30 to 10h30 . From 9 am to 15pm, my app traffic was high, and the rest was low, in the high traffic time loki write resource was consumed a lot, and I see that the data mostly lost at this time of the current day, and the next day it was appeared. Is there any relative of the write component with the queries?
I haven’t seen the issue come back anymore , Thank you @tonyswumac@fadjar340 so much!
But sometimes in high traffic time, the metrics are too slow (never timeout, hang forever) to be got even if I set the time range as 5 minutes ago (the first code block), but I query the log alone, it’s fine (the second code block).