Hello, I have Grafana Tempo in a single binary installation. There are 2 replicas of tempo binary.
And the problem is that I got completely different results when I execute the same search query (by traceid) a couple of times. I tried to put query frontend in front of querier but got the same
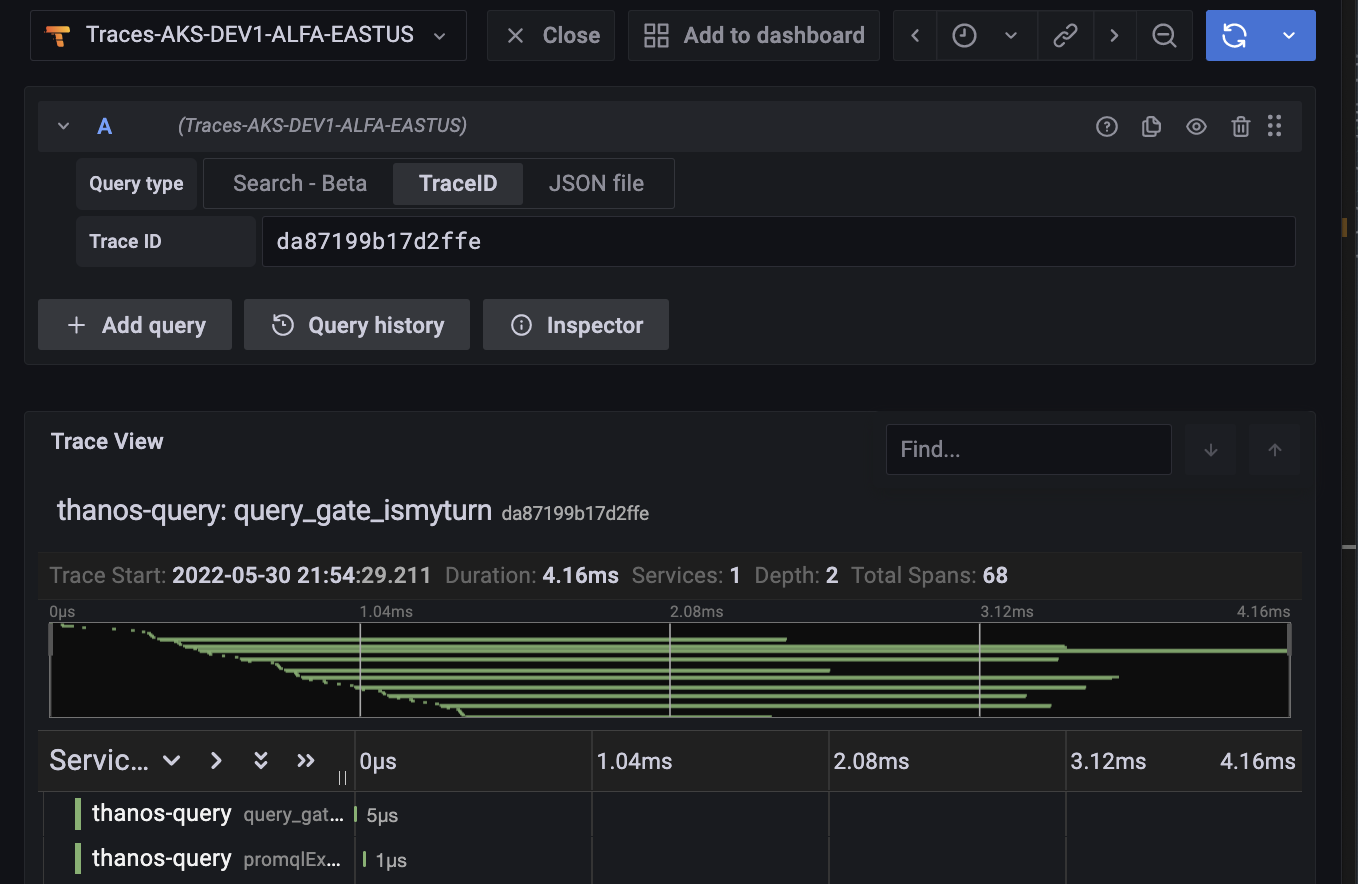
here is result #1:
The single binary deployment is generally intended as an easy to operate, but not-scalable solution. There are ways to get the single binary be horizontally scalable, but it won’t work that way by default:
Also, note that for any of the scalable solutions to work you will need to use an object storage backend. Local disk will not work.
I’ve switched to simple-scalable, but still have this issue. And sometimes it even says 404 Not found for the traceid and provides the information on the next query run:
Hello @joeelliott .
There are 2 Tempo PODs in the Kubernetes cluster. Also, there are 2 Query Frontend PODs in front of the Tempo. Tempo PODs configured with -target=scalable-single-binary argument.
I’ve tried configuration without QueryFrontend (ingress->K8service->PODs) but got the same result.
Tempo reads data directly from the Kafka topic.
Here is a configuration
Regarding system behavior, it can return 404 or the successful result without any pattern. So you can get a couple 404 in raw and then a successful and then 404 again. To me, it looks like related to which Tempo POD is serving my query. Another case is on the first screenshots: when the same query for the same traceid returns completely different results. Again, looks like the whole trace was divided into two parts, And the query returns only the part which is present on Tempo POD that is servicing the query request. What is interesting, is that over time, it starts to return the correct value (of full, joined trace) all the time. When I’ve decreased the number of Tempo PODs to 1 replica everything works correctly.
We have traces from the Nginx ingress controller, Thanos query, and other systems, and the behavior is the same for all of them.
And there are no errors in the log
For Tempo to work when it’s deployed in a scalable fashion (either as scalable single binaries or as microservices) the components have to be aware of each other.
Right now your queriers are only querying the local ingester b/c that’s the only ingester they know exists. This is why the trace returning is conditionally based on which querier pulled the job. If you waited long enough for that trace to be flushed to your azure backend then i would expect it to return everytime instead of 404ing about half the time.
In order for Tempo components to know that the others exist they rely on propagating a data structure called the ring. There are a few of these and each one coordinates a different set of components:
The easiest and most battle tested way to propagate the ring(s) is to use memberlist. This is a gossip protocol and requires no additional components to be deployed. The memberlist configuration requires a list of IPs or a DNS address that resolves to a set of IPs. Example here:
This docker compose example simply lists DNS names for the 3 different shards. If you had a single DNS entry that resolved to all 3 IPs that would work too.
Hopefully this will resolve your issue. If not, let me know!
hello @joeelliott
I have the same issue again and can’t understand where to look at.
But this time I have Tempo in distributed mode.
here is a full config: