Hi, I am trying to increase the resource allocation to the runner pod as the test cases that are executed are pretty big and the runner pods keep getting OOMKilled.
When I described the runner pod, I see the pod had been using the default settings even though I increased the resource allocation.
apiVersion: k6.io/v1alpha1
kind: TestRun
metadata:
name: k6
spec:
parallelism: 1
cleanup: post
arguments: -o experimental-prometheus-rw --tag testid=call-report_2
script:
configMap:
name: demo
file: archive.tar
runner:
env:
- name: K6_PROMETHEUS_RW_SERVER_URL
value: "http://prometheus-kube-prometheus-prometheus.monitor.svc.cluster.local:9090/api/v1/write"
- name: K6_PROMETHEUS_RW_TREND_AS_NATIVE_HISTOGRAM
value: "true"
resources:
limits:
cpu: "3000m"
memory: "25Gi"
requests:
cpu: "2000m"
memory: "25Gi"
Below is the resources that were actually allocated to the runner pod. Why wasn’t the increase of resources applied?
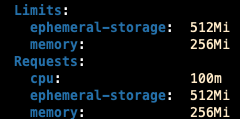
Hi @zzhao2022
It is wierd, because it should work like that.
For me this works:
apiVersion: k6.io/v1alpha1
kind: TestRun
metadata:
name: perf-test
spec:
parallelism: 1
script:
configMap:
name: perf-test
file: perf-test.js
runner:
resources:
limits:
cpu: "300m"
memory: "250M"
requests:
cpu: "300m"
memory: "250M"
In the descriptor of the created runner pod I can see:
...
resources:
limits:
cpu: 300m
memory: 250M
requests:
cpu: 300m
memory: 250M
...
Did you delete the TestRun resource before updating it?
Hi @bandorko,
I am not sure what was the fix. I re-deployed k6-operator from the beginning. And it works now. I see the custom resource allocation settings are applied to the runner pod correctly now.
I have a follow-up question. The test case I plan to run via k6-operator is quite large. It could consume more than 25 GB mem when I was testing on my local because the test case contains multiple scenarios. So in this case, besides increasing resources for the runner pod, do I also need to increase the resources for the manager pod, starter pod and initiate pod? And is there any resource limit? For example, is there any issue if I request like 25 GiB of memory for the runner pod?
Is there any recommendations for running big test case? I don’t see any in the documentation.