Hi @gabrielgiussi1,
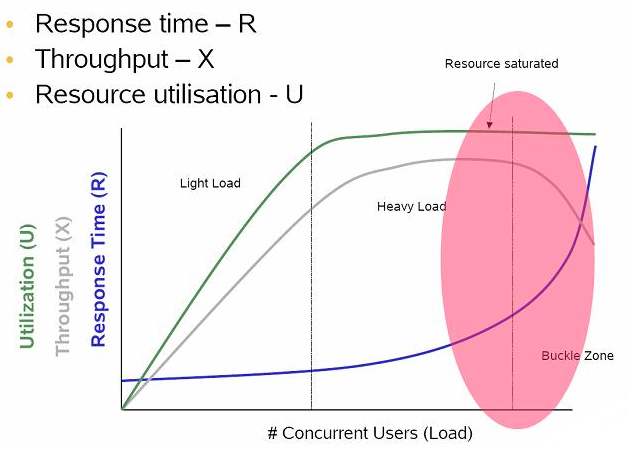
Looking at the first graph, you have found the zone - 300 RPS is what the current setup can handle.
Adding more VUs has the same throught put - which likely will fall if you sustain longer or increase the VUs more.
Although maybe it won’t depending on what the limitation is here. AFAIK this illutration depends on there being some finite resource that runs out and requesting more of it while it is not available will degrade the performance. But that might not be true or might be hard to observe.
For example if in your case you are badwidth limitted by your network interface (with 300 RPS you need 41kb per request for 100mbps or 410kb per request for 1gbps) adding more requests will likely not decrease the performance any more until you start making the interfaces inbetween not being able to keep up with all the connection states. Which is unlikely before you hit hundreds of thousands if not even million of connections.
On your other points:
The arrival rate graph seem off to me. THe VUs go to their target values half way through there being a ton of requests which seems way off.
Looking at the timeline they are aligned so I have no idea what is happening  .
.
I couldn’t even make sense of the k6 behavior in relation to the configuration I’m setting.
I don’t know what is confusing to you and I see that you spell out exactly how the executors work.
Both executors (ramping-vus and ramping-arrival-rate) have a set of stages that they go.
One (ramping-vus) changes how many VUS are active during this stages. And each VU just loops and does the iteration as fast as possible. This means that if there are supposed to be 100 VUs your test will have 100 JS VM constantly looping over the default function.
Whether that will mean there will be 100 RPS or 1000 or 1 - depends entirely on how fast the system under test (SUT) answers (and what the scritp does, but let’s say it is something that is mostly dominated by the SUT). That does mean that if you have a SUT that returns in 5ms you will get a bunch of requetss done. But if the SUT starts returning slowere the 100 VUs will stil be doing only 100 requests (simplified). This is called closed model as the SUT influences how it is tested.
The ramping-arrival-rate has a number of VUs (I recommend not setting maxVUs, just use preallocated VUs) which will do a number of iterations (the target in that case) and that number changes. More accurately it will try to start that many iterations. K6 runs js code and that js code needs a VM to run in. And JS is single threaded by design. So only one iteration can be run by any given VU at any given time and it needs to finish before a new one can start.
But if you want to have a test that test that you system can continously match a given iteration rate (as RPS is not really a thing k6 understand all that much) - you can have an arrival-rate executor with that rate setup and a bunch of VUs and it will keep that rate if possible. If not it will emit dropped_iterations.
While the rate of the starting iterations is not based on the SUT returning results. We are still limitted by that in how many in flight iterations we have.
But wtih ramping-vus makign k6 keep a given iteration rate invovled a bunch of sleep and calculations, which is very troublesome to get right.
So ramping-vus will loop a changing/ramping number of VUs and get as much as possible.
Arrival-rate tries to reach a given rate of iteration starts and if not will signal that.
You can choose either one depending on what you want to test.
I would probably go with 5k VUs or something like that adn a fairly slowly ramping rate taht also stays at given levels for a minute or two.
Hope this helps you and sorry for the long reply