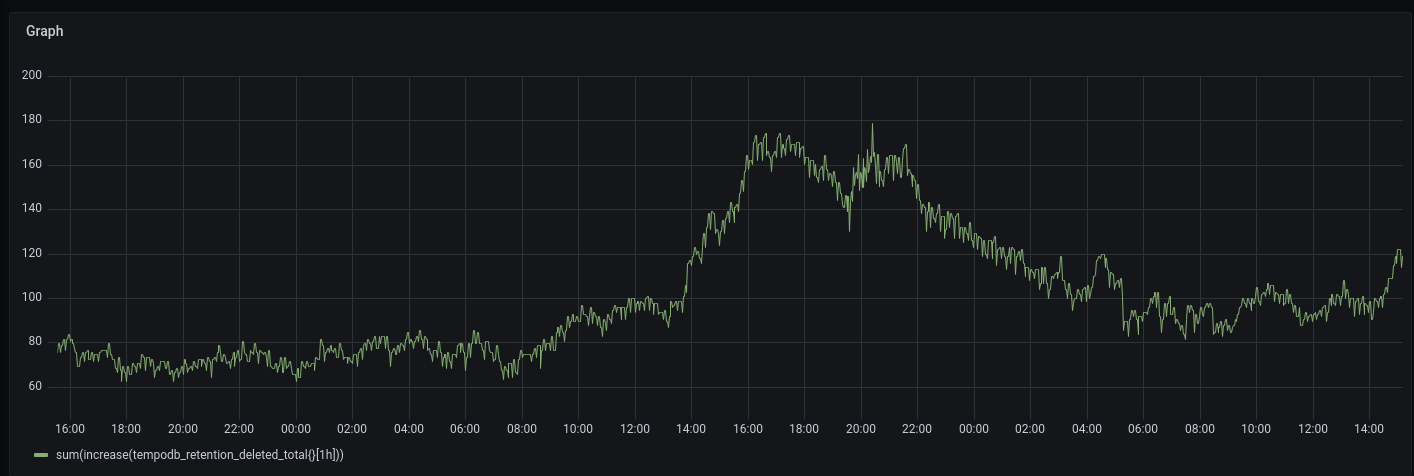
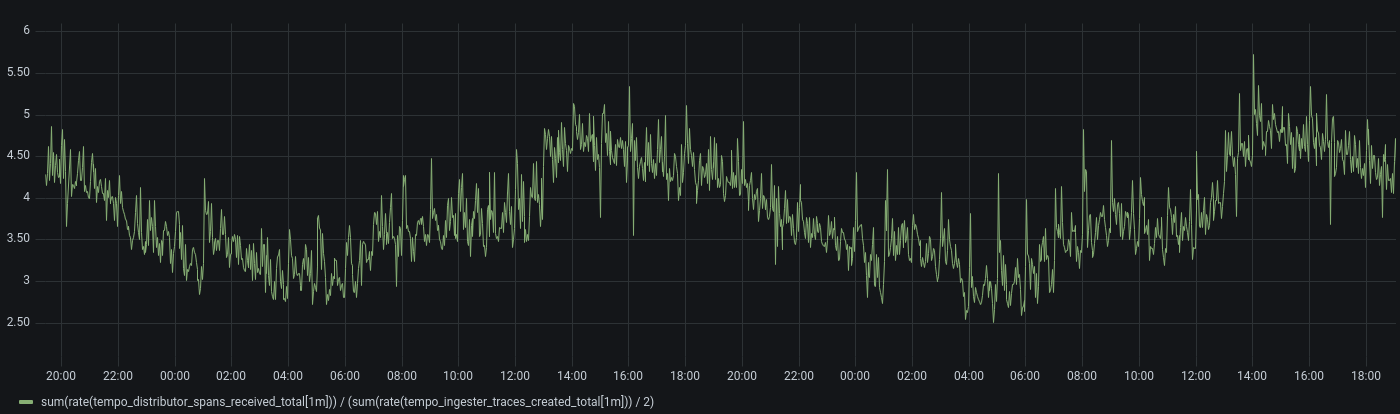
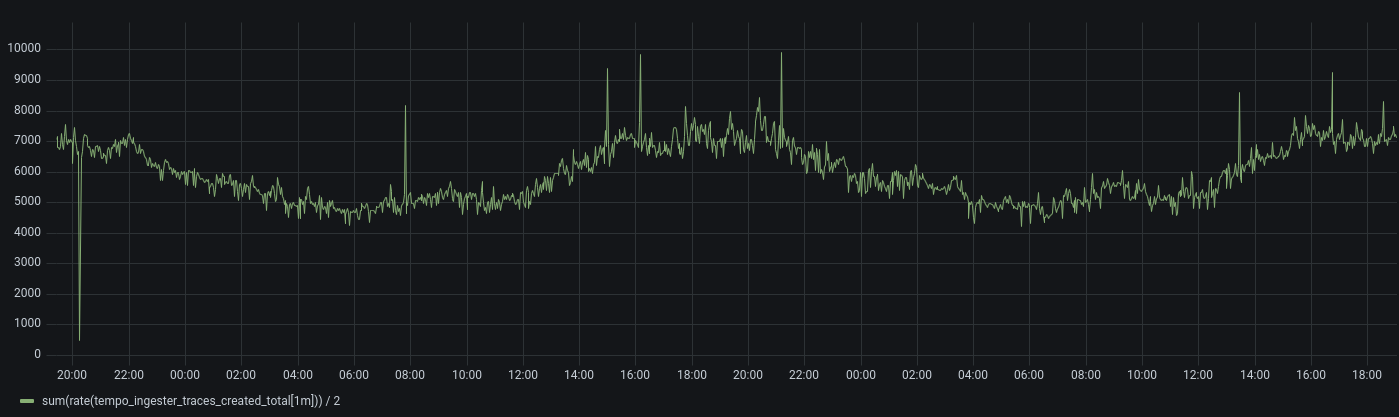
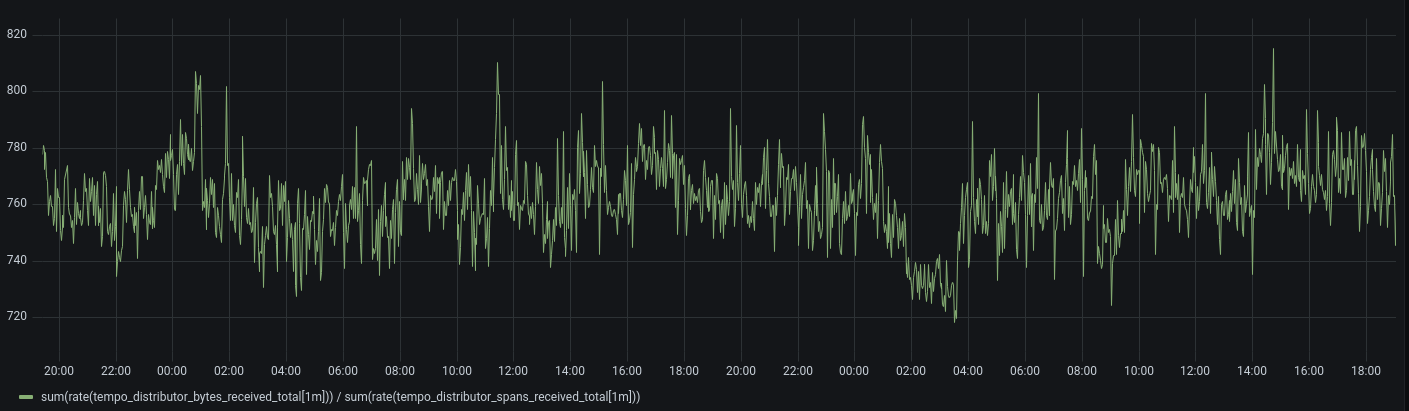
Traces cannot be found in S3 after they have been flushed from the ingesters.
The query will return a 404 instead.
Our 0.5.0 install seemed to work fine for awhile (30+ days) until we noticed we
could not pull traces from S3 about 30mins after they were generated. The
querier logs msg="failed to retrieve block meta" and found=false messages
while looking in blocks for the traceids.
Some of the blocks in S3 seemed to be incomplete. Only containing bloom-# and
index files, but not meta.json or meta.compacted.json files.
I shutdown all the app components, wiped the S3 bucket contents, and brought it
back up with version 0.6.0. Seemed to work again for about a week. I was initially
able to pull traces older than 45mins. The queriers logged found=true messages
for queries. After about a week, the 404s started to occur again.
The only outlier I’ve found so far is that the compactor started logging
msg="failed to get ring" and had no live replicas in the ring. I’ve shutdown
all the components and restarted the memberlist ring, but that did not help.
tempo configmap (distributor/ingester/compactor)
data:
overrides.yaml: |
overrides: {}
tempo.yaml: |
auth_enabled: false
compactor:
compaction:
block_retention: 360h # duration to keep blocks
compacted_block_retention: 1h # duration to keep blocks that have been compacted elsewhere
compaction_window: 1h # blocks in this time window will be compacted together
chunk_size_bytes: 10485760 # amount of data to buffer from input blocks
flush_size_bytes: 31457280 # flush data to backend when buffer is this large
max_block_bytes: 107374182400 # Maximum size of a compacted block in bytes. 100GB
ring:
kvstore:
store: memberlist
distributor:
receivers:
jaeger:
protocols:
thrift_http:
grpc:
thrift_binary:
thrift_compact:
opencensus: null
otlp:
protocols:
http:
grpc:
zipkin:
ingester:
lifecycler:
ring:
replication_factor: 2
trace_idle_period: 30s
max_block_bytes: 1_000_000_000
max_block_duration: 1h
memberlist:
abort_if_cluster_join_fails: false
bind_port: 7946
join_members:
- tempo-gossip-ring.telemetry.svc.cluster.local:7946
# rejoin_interval: 15m
overrides:
max_traces_per_user: 1000000
per_tenant_override_config: /etc/tempo/overrides.yaml
server:
http_listen_port: 3100
storage:
trace:
backend: s3
blocklist_poll: 5m
block:
encoding: zstd
cache: redis
pool:
max_workers: 50
queue_depth: 2000
redis:
endpoint: tempo-redis:6379
timeout: 500ms
s3:
bucket: example-prd-tempo-storage
endpoint: s3.us-west-2.amazonaws.com
insecure: true
# region: us-west-2
wal:
# bloom_filter_false_positive: .05 # bloom filter false positive rate. lower values create larger filters but fewer false positives
path: /var/tempo/wal
tempo-query configmap
data:
tempo.yaml: |
auth_enabled: false
ingester:
lifecycler:
ring:
replication_factor: 2
memberlist:
abort_if_cluster_join_fails: false
bind_port: 7946
join_members:
- tempo-gossip-ring.telemetry.svc.cluster.local:7946
overrides:
per_tenant_override_config: /conf/overrides.yaml
querier:
frontend_worker:
frontend_address: tempo-query-frontend-discovery.telemetry.svc.cluster.local:9095
server:
http_listen_port: 3100
log_level: info
storage:
trace:
backend: s3
block:
encoding: zstd
blocklist_poll: 5m
cache: redis
redis:
endpoint: tempo-redis:6379
timeout: 500ms
s3:
bucket: example-prd-tempo-storage
endpoint: s3.us-west-2.amazonaws.com
insecure: true
# region: us-west-2
pool:
max_workers: 200
queue_depth: 2000
wal:
path: /var/tempo/wal
tempo-query-frontend configmap
data:
tempo.yaml: |
auth_enabled: false
ingester:
lifecycler:
ring:
replication_factor: 2
memberlist:
abort_if_cluster_join_fails: false
bind_port: 7946
join_members:
- tempo-gossip-ring.telemetry.svc.cluster.local:7946
overrides:
per_tenant_override_config: /conf/overrides.yaml
query_frontend:
query_shards: 10
server:
http_listen_port: 3100
log_level: info
storage:
trace:
backend: s3
blocklist_poll: 5m
block:
encoding: zstd
cache: redis
redis:
endpoint: tempo-redis:6379
timeout: 500ms
s3:
bucket: example-prd-tempo-storage
endpoint: s3.us-west-2.amazonaws.com
insecure: true
# region: us-west-2
pool:
max_workers: 200
queue_depth: 2000
wal:
path: /var/tempo/wal